
Institutions often only want to archive the PDF files that are part of a site. With our "PDF only crawl" feature, you can crawl entire sites and collect only the PDF files.
On this page
- Running a PDF-Only One-Time or Test crawl
- Scheduling PDF-Only Crawls
-
Accessing archived PDFs from PDF-Only crawls
Running a PDF-only One-Time or Test crawl
After selecting seeds and clicking the Run Crawl button, select the Crawl PDFs Only checkbox in the Run Crawl dialogue, then click Crawl.
Scheduling PDF-only crawls
Navigate to the list in the "Crawls" tab for your chosen collection. For any crawl that you wish to limit to PDF-only, click on its corresponding "Edit Limits" button:
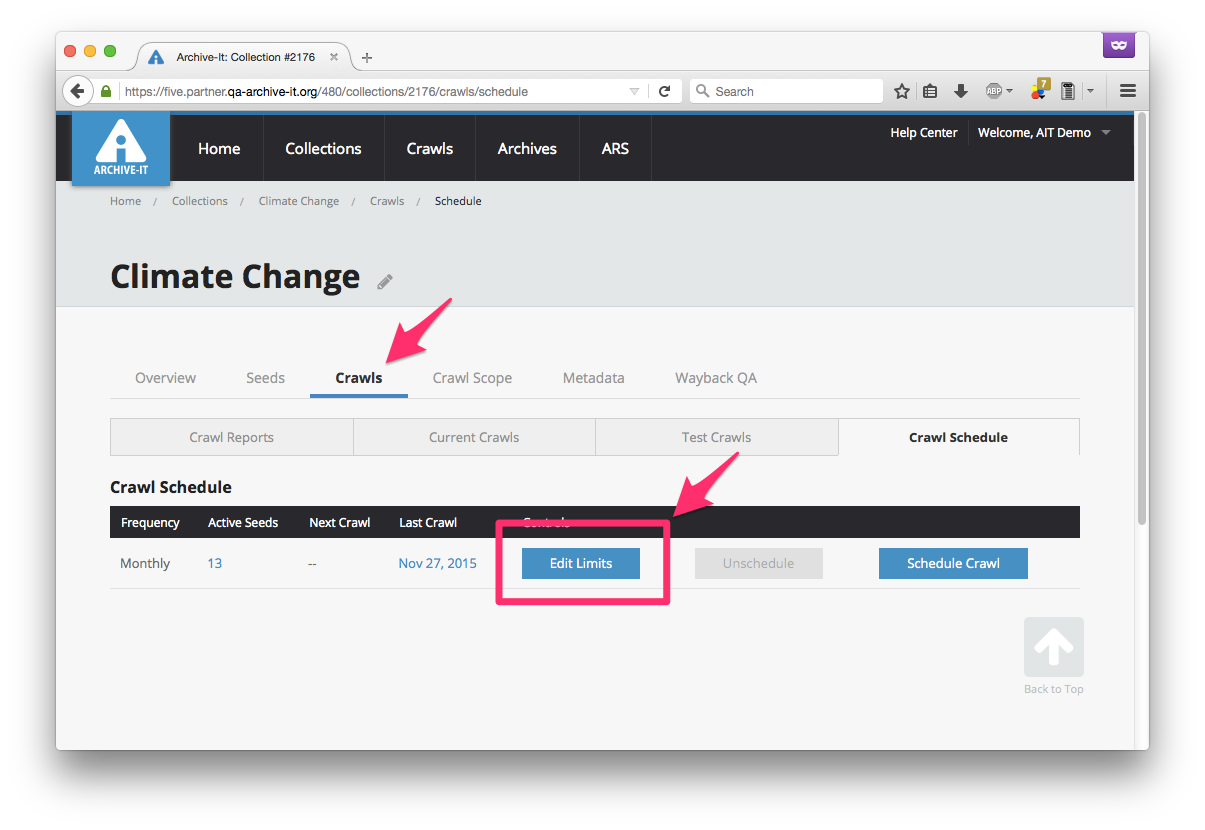
Then, in the dialog box that this button opens, click the checkbox next to the "PDF only crawl" option:
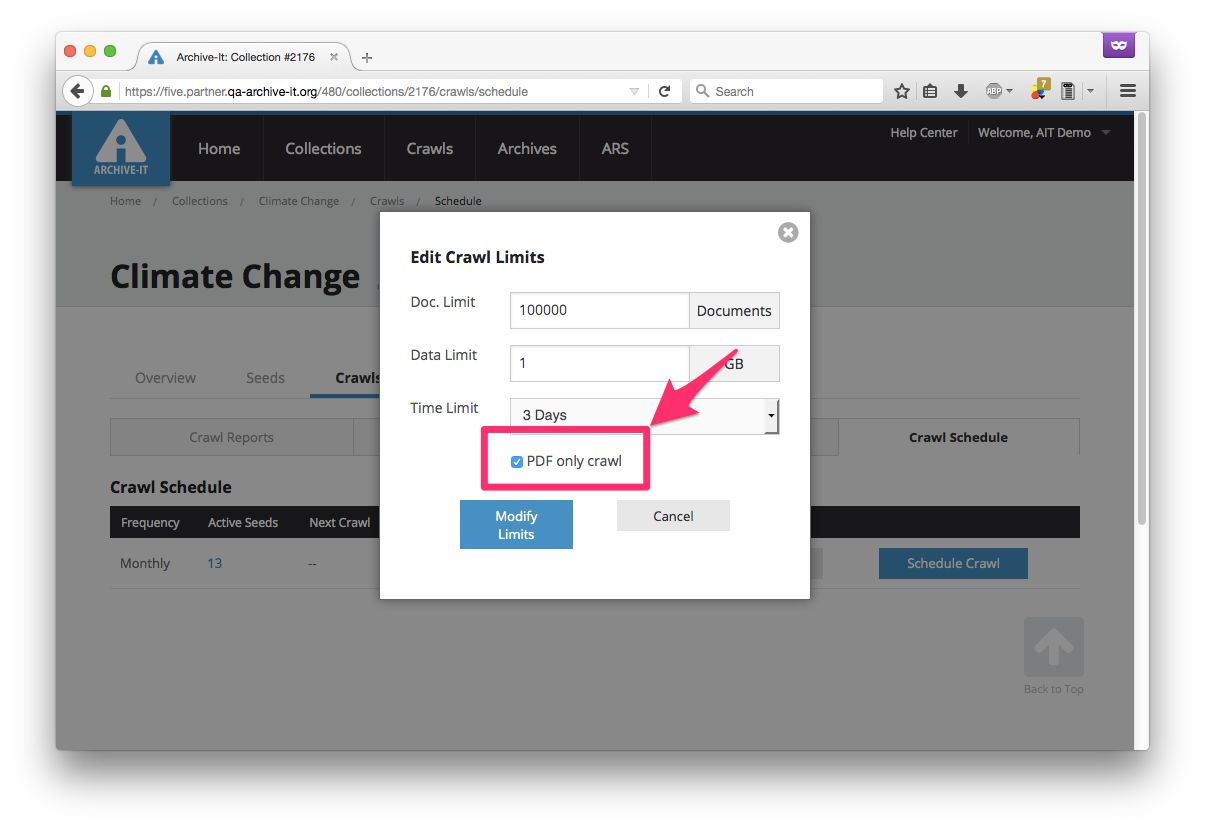
End by clicking the Modify Limits button to save the setting. The next time the crawl runs, it will collect only PDF files.
Accessing archived PDFs from PDF-Only crawls
PDF-only crawls function similarly to standard crawls but are configured to collect only PDF files discovered during the crawl. It's important to note that the seed's homepage typically won't be captured in this type of crawl. As a result, the seed's Wayback link will not display a capture from the PDF-only crawl.
Accessing PDFs
- Open the File Types tab in your crawl report.
- Click the application/pdf link.
- You'll see a complete list of the collected PDFs, along with links to their archived versions in Wayback.
PDFs from a PDF-Only crawl will also be accessible via archived versions of the site from other crawls or via full-text search.
Comments
0 comments
Please sign in to leave a comment.