numCapture/capture dates discrepancy in HTML v. JSON

Hi,
I'm seeing different values for numCapture, firstCaptureDate and lastCaptureDate depending whether I request the data as html or JSON. Specifically, it looks like numCapture is zero and capture dates are "Jan 01, 1900" for all results in the JSON data.
Should I be passing additional parameters specifying a date range when requesting the data in JSON format? If so, could someone provide the correct syntax? (My attempts haven't worked.)
For example, for this URI, https://archive-it.org/collections/1068, the first result shows these values:
Captured 56 times between May 14, 2009 and Oct 22, 2018
But for this URI, https://archive-it.org/collections/1068.json, the first result contains these values:
"numCaptures": 0,
"firstCapture": {
"waybackUrl": "https://wayback.archive-it.org/1068/19000101000000/http://aappb.org/",
"date": -2208988800000,
"formattedDate": "Jan 01, 1900"
},
"lastCapture": {
"waybackUrl": "https://wayback.archive-it.org/1068/19000101000000/http://aappb.org/",
"date": -2208988800000,
"formattedDate": "Jan 01, 1900"
}
Thanks,
Jack
-

Thanks for pointing this out, Jack! Here's where and why you can find that missing Wayback capture information:
The information that you see on archive-it.org collection pages is actually drawn from two different sources: seeds and their descriptions are queried from our Solr index while the Wayback data (the capture numbers and dates) are pulled from a CDX file--the index file for all records in the archival replay interface. So here's how that breaks down in practice:
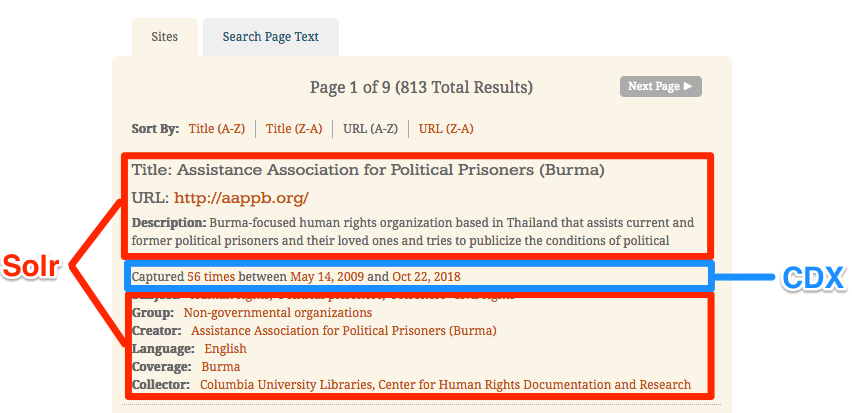
Each collection, like the one at https://archive-it.org/collections/1068, has its own CDX file and API endpoint as well. This "CDX/C" API provides quick access to plain text data about all captures, which we in turn use for instance to plug in the counts and the dates for first and most recent captures. The API is documented here in Archive-It's Help Center and you can see it used in practice to retrieve and represent the same kind of information that you seek in examples like these web archives by Princeton Theological Seminary. PTSEM queries the CDX/C API to produce the "Capture Dates" browsing module for each of its sites cataloged there.
Hope this helps you and everyone watching from home to retrieve the necessary Wayback info for presentation in your own access layers, but let us know how it works for you.
Please sign in to leave a comment.
Comments
1 comment