How to capture COVID-19 web pages across your domain

Hi all,
There’s been a lot of collecting around the Coronavirus and its effects on our communities. Some of these web archives are very specific and others are quite broad. Recently, one of our partners asked if there were a way that they could simply capture any pages on their domain that had “covid” or “coronavirus” in their URLs, without having to seek them out precisely across disparate sites and sub-domains, nor to scope in anything from endless sites across the web.
There is! And you can adapt it to fit a web crawl of your own institution’s domain, to catch anything COVID-related that may require preservation and curation.
To collect all of this material, expand your scope to include all URLs that match your version of this regular expression:
^https?://([^.]*\.)*mydomainhere\.edu/[^.]*(coronavirus|covid).*$
Just swap in your own institution’s domain where indicated (and if necessary, adjust the TLD like .edu, .com, or .org) so you get a new scoping rule that looks like this one for the archive.org:
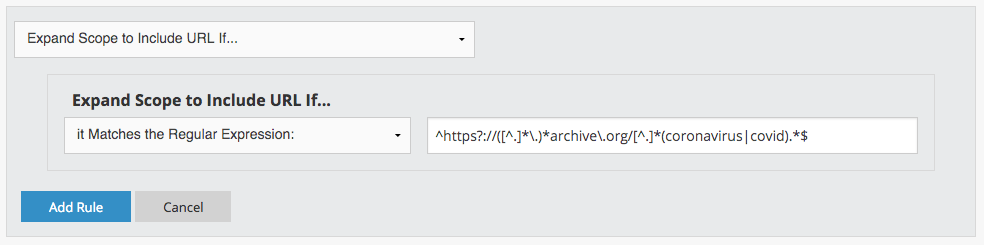
You can adapt this regular expression even further from there if you like -- there’s no strict limit to the URL terms that you can scope-in by adding them to the parenthetical space above, separated by more vertical bars. (You could adapt this to non-virus use cases as well).
Just don’t forget to test! There’s always a risk of getting much more than you bargained for with scope expansions. Be sure to run a test crawl to completion with your new scoping rule before spending any of your data budget and save only the successes.
And let us know as always if we can help you with this rule or another one like it.
Please sign in to leave a comment.
Comments
0 comments