
Overview
Wayback QA is an automated quality assurance tool. It scans the Wayback page you're viewing and identifies documents that were not captured initially by the crawler (blocked by robots.txt, out of scope, etc.). It then gives you the option to patch those documents back into your Wayback page with a patch crawl. This article provides step-by-step instructions for using the Wayback QA tool to start patch crawls.
Prerequisites
Wayback pages with yellow banners from saved test crawls or production crawls (One-Time or Scheduled). You must also be logged into your Archive-It account in the same browser.
On this page:
Enable Wayback QA
Browse your Wayback pages until you find content missing from the page you are currently viewing. If the page is missing embedded elements like images, stylesheets, or other functionality, patch crawls can help.
To activate the Wayback QA tool to detect missing URLs for your patch crawl:
- Click the Enable QA link in the yellow banner.
The page will reload and the link will change to Disable QA, which indicates that the QA tool is activated. - Browse the Wayback page(s) with missing content again to detect the Missing URLs.

View Missing URLs
When you finish browsing Wayback pages with missing content:
- Click the View Missing URLs (# detected) link in the banner.
A new tab opens in your Archive-It account's Wayback QA tab for that collection, which lists the missing URLs detected from the last URL viewed. - Select Disable QA in the banner.
This deactivates the Wayback QA tool and you can proceed to selecting documents for your patch crawl.

Select Documents
In your Archive-It account's Wayback QA tab, the Missing Documents subtab presents a table of missing documents filtered by the last Wayback URL viewed. To clear the filter and see a list of all missing documents for the whole collection, click the X. You can then use this filter to find specific URLs or file extensions.
To select the missing document(s) that you want to include in your patch crawl, click the checkbox next to the Missing Document URL.
The table's columns may help select these Missing Document URLs:
- Missing Documents – URLs detected as missing by the Wayback QA tool.
- Doc. Missing From – URL for the live web page the document is from.
- Possible Reason* – Why the missing document was not archived during the initial crawl.
- File Type* – The MIME type of the Missing Document, such as image/gif, text/html, etc.
- Size* – The data volume of each missing document.
- Crawl Date – The date for the crawl that collected the Wayback page.
*We are aware that the Possible Reason, File Type, and Size columns are not displaying expected values at this time and are working to resolve this issue.
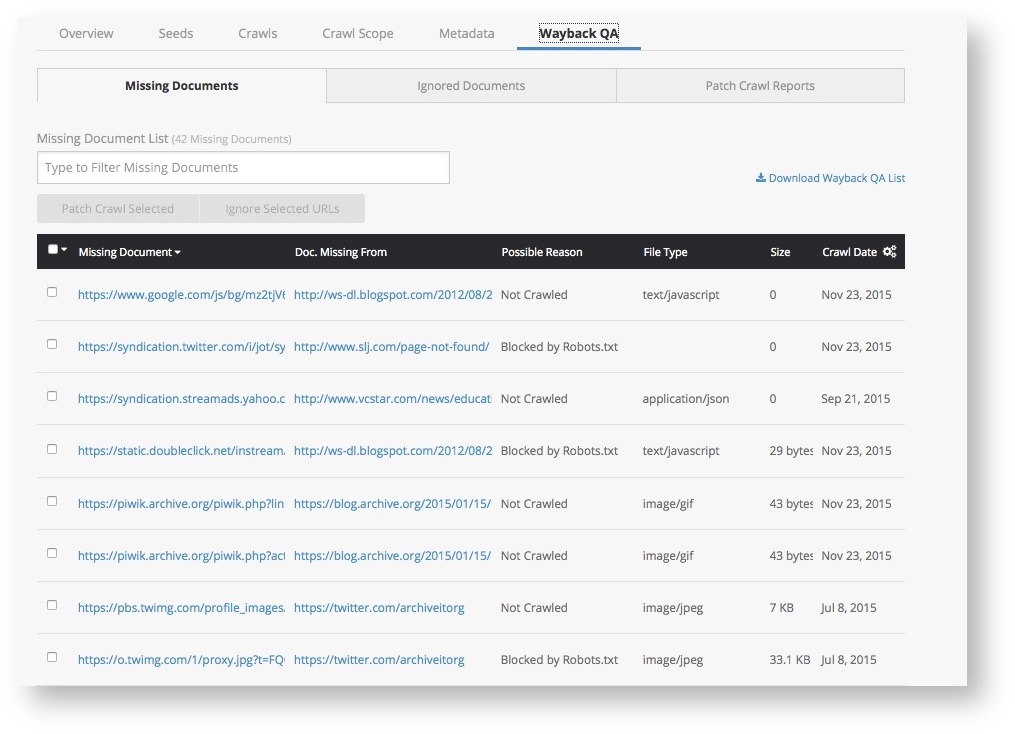
Some missing documents will not add value and don't need to be patch crawled. This includes invalid URLs, advertising, and customer tracking, as well as out-of-scope URLs. To exclude such URLs from your patch crawl, click their checkboxes, and then select the Ignore Selected URLs button. The ignored URLs are moved to the the Ignored Documents subtab.
Run patch crawls
After you have selected the missing documents that you want to patch crawl:
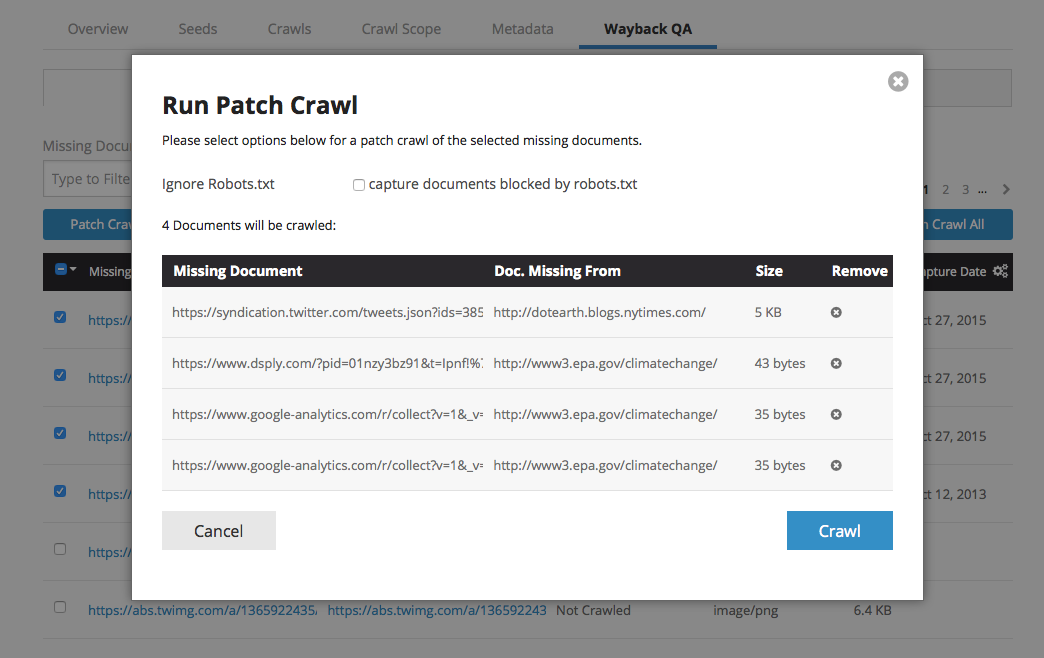
- Click the Patch Crawl Selected button. A box opens to launch the patch crawl.
- Click the Ignore Robots.txt checkbox.
- Click the Crawl button to start your patch crawl.
Outcome
The patch crawl will be added to your list of current crawls. The patch crawl will only collect the individual documents in your patch crawl list. Patch crawls will not follow links off of documents and do not adhere to scoping rules.
When completed, you can see the crawl report in the Wayback QA tab under the Patch Crawl Reports subtab.
Patch crawls take up to 24 hours after completion before they will be available in Wayback. View your Wayback page again for improved replay.
Related content
How to change scope and run patch crawls from your Hosts report
Comments
0 comments
Please sign in to leave a comment.