
Archive password protected content - ALPHA
Partners will have the option to capture content that is only accessible through a username and password. Partners can enter login credentials on the seed settings page for a specific seed with password protected content and the crawler will use those credentials to capture the password protected content.
And, as with all archived content in Archive-It, private/restricted access will continue to be available.
Please note that this feature is in its Alpha phase and we encourage our partners to try out the feature and provide feedback to Archive-It support. Because of the varied ways that login forms work technically, some password protected sites (including Facebook and LinkedIn) may be more difficult for the crawler to gain access to than others. If you have any questions as you're using this feature, please contact Archive-It support.
You can find more information on using this feature here.
"Smart" Deduplication
This feature allows the crawler to automatically determine whether the contents of a URL are identical to a different URL that has already been archived, in which case the crawler will not archive a duplicate copy of the file, and the data will not count against your budgets. Some common examples of cases where this feature will be useful include websites where http and https versions or www and non-www versions of URLs have identical content.
Select specific seeds for a one time crawl
This feature will allow partners to run a one-time crawl on selected seeds within a specific frequency or across different frequencies. This could be useful if you want to crawl one or more seeds in a reoccurring frequency in-between regularly scheduled crawls, or if you want to crawl seeds that are in different frequencies together, without moving them from one frequency to another.
This feature can be accessed from the Seed Management area of the application and works much the same as starting a Test Crawl on seeds in an existing collection. Check the checkbox to the left of the seed(s) you would like to include in the crawl and then click the "Crawl Selected Seeds" button. This will allow you to adjust the crawl duration, as well as any document or data limits, and review your seed list before initiating the crawl.
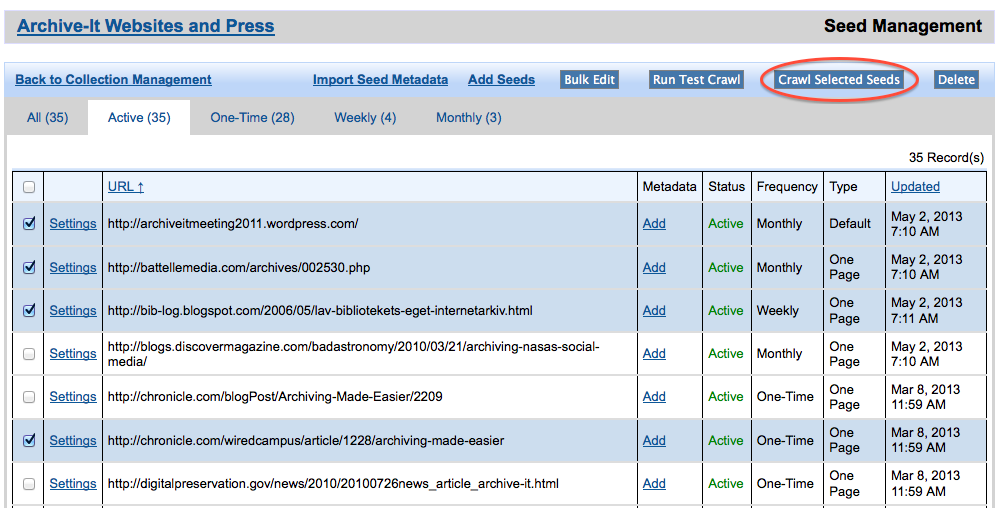
Run test crawls and one-time crawl simultaneously
In the past, one-time and test crawls were linked and a one-time crawl could not be initiated while a test crawl was running. Now, one-time and test crawls can run simultaneously. In addition, when a test crawl is running for a collection, the test crawl will now appear on the Collection Management page under "Crawling Activity".
Option to adjust politeness settings for crawls
The standard politeness settings for the Archive-It crawler generally allow it to capture one URL at a time from each host that is being crawled, at a rate of one URL per second. With the H3 crawler, we have the ability to adjust the politeness settings to crawl specific sites more quickly. Please let the Archive-It staff know if there is a site that you would like to be crawling more quickly and we can adjust the politeness settings in your crawl of that site.
Crawl Analysis/Scoping
Wayback QA Tool
This feature will complement the existing QA Tool by automatically identifying any missing URLs while a user is browsing in Wayback, and allowing partners run a Patch Crawl to capture any missing URLs. This feature will allow partners to perform QA on additional pages beyond their seed URLs, and the Wayback software can often identify and capture URLs that the crawler was not able to discover.
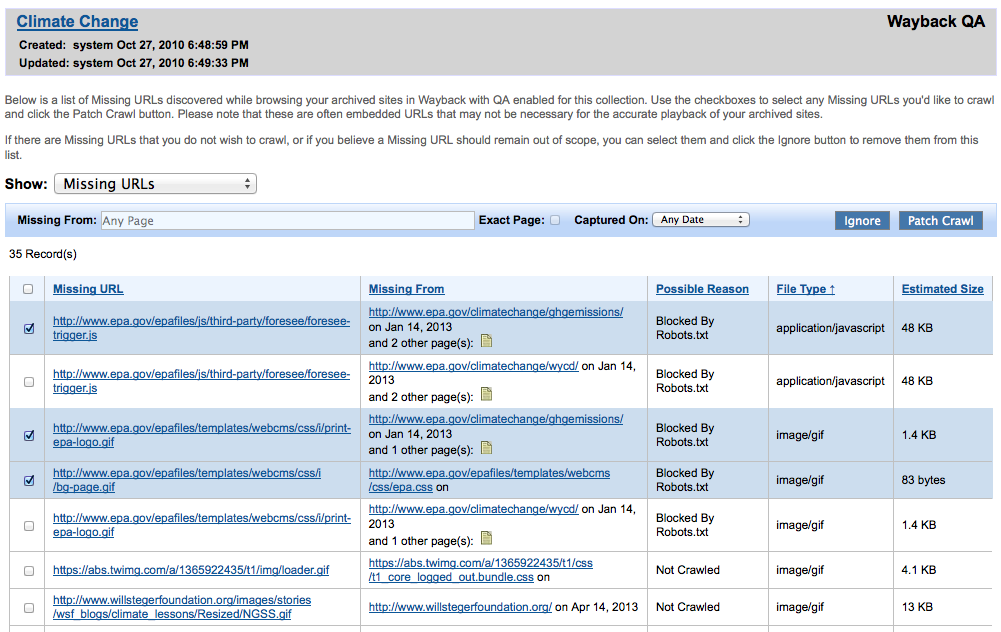
When partners are logged into their accounts and browsing in Wayback, a link will appear in the Wayback banner to "Enable QA". With this option enabled, Wayback will record any URLs that are missing on pages that a user is browsing, and allow partners to easily access a list of Missing URLs from a given page by clicking on the "View Missing URLs" link in the Wayback banner.


From the Missing URLs page, partners can review which URLs were missing and why, and then run a patch crawl in order to capture the missing URLs.
You can find more information on using this feature here
'File Types' report links to lists of corresponding URLs
In the File Types report, the numbers in the URLs column for each file type will now link to the list of URLs of that file type. This feature will be in place for any crawls that run after our 4.8 release. (May 2, 2013)
Note: The file type for a specific URL is designated by the web designer. There may be discrepancies between the stated file type and the actual file type.
Sort PDF Report by New URLs
We have added a "New URL" column to the PDF Report that allows you to see whether a PDF captured in a specific crawl is new or has changed since its previous capture date. You can also sort the PDF list by the "New URL" column. This feature will be in place for any that crawls run after our 4.8 release. (May 2, 2013)
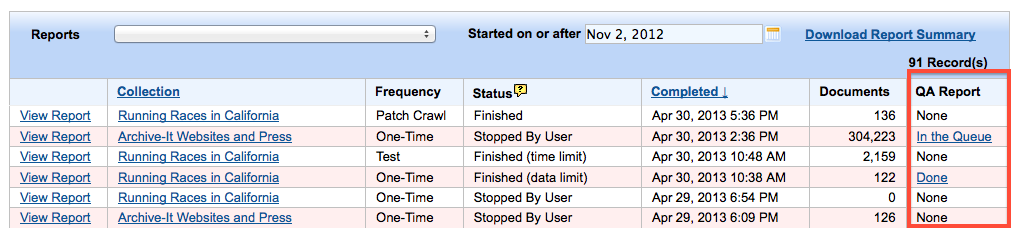
QA Report Column on Reports listing page
Partners will now see a "QA Report" column on the reports listing page that lets you know whether a QA Report has been generated or is in process for a specific crawl. If a QA Report has been generated, there will be a link to easily access the QA Report from the listing page.
Access
IP authentication for Wayback access
Partners now have the option to restrict access to their archived content at the collection level to only those users who are in their reading room, or another specific IP range at their location. Patrons who try to access content outside of the IP range (for example, a home computer) will see an 'Access Denied' message, which can be customized for your organization.
If you would like to utilize this feature for your organization, please notify the Archive-It team by Submitting a Question within your account. Please designate the collection(s) you want to restrict, as well as the allowed IP range. In addition, you may provide us with a customized Access Denied message, which could include contact information for your organization for patrons who have questions about where they can access restricted content.
Remove archived content from full text search
This is an extension of the current feature that allows partners to request the exclusion specific URLs, hosts, or capture dates from being displayed in Wayback by contacting Archive-It support. In this release those Wayback exclusions will also be applied to full text search results, so that blocked content is not indexed for search. Content will be removed from the search index following the next crawl run on a collection after an exclusion is added.
You can find more information on restricting access to archived content here
Ability to customize your Organization URL on archive-it.org (
http://archive-it.org/home/yourcustomURL)
By default, your public Archive-It.org homepage is a unique URL, and looks like this: http://archive-it.org/organizations/398 , where 398 is the unique number for your organization (this number is also reflected in your archived content's Wayback URL). You have the option of creating a more personalized URL for your organization's Archive-it.org landing page, that looks like this: http://archive-it.org/home/mylandingpage, where "mylandingpage" can be customized for your organization. Administrator users can customize this URL by going to the Admin section of your Archive-It Account. On the Account Settings tab, in the Public Site Options area, you can input the Custom URL of your choice.
Metadata
Import seed and document level metadata
Rather than editing and adding metadata one seed or document URL at a time, partners can upload a .ODS (Open Office Spreadsheet) format file, to create custom fields, add metadata, or replace existing metadata.
More information about this feature, as well as a downloadable .ODS file to use a template can be found here
Seed level metadata OAI-PMH feed
For those partners who have opted to include their collection level metadata in Archive-It's OAI-PMH (Open Archives Initiative - Protocol for Metadata Harvesting) metadata feed, seed level metadata will now be included in a separate feed, specifically for seed level metadata. This can be enabled from the collection metadata screen, by checking the " Export Metadata to OAI-PMH (including WorldCat)" checkbox. While the collection level OAI-PMH feed is most commonly used to expose Metadata to WorldCat, the seed level feed will not automatically be exported to WorldCat at this time. We encourage our partners to take advantage of the OAI-PMH feed's other uses, including the ability to create visualizations of digital collections with ViewShare, and increased integration with external catalogs or search services.
More information about the OAI-PMH feed can be found here.
Other things you may notice
Phased out active collection and seed limits
Partners no longer have restrictions on the number of collections or seeds they may have active at one time. Please still consider your document and data budgets when making crawling frequency decisions.
Public site display enhancements
New features have been added to the public site to allow metadata facets to be sorted alphabetically or by the number of records that contain that metadata facet.
Additionally, all metadata now displays below each individual collection, seed, and URL listed to the right of the metadata facets.
Templates
Since the initial launch of the Templates feature that allowed partners to create a custom organizational homepage including a custom URL, we have redesigned the public Archive-It.org site to be more customizable and to allow for more extensive use of metadata. We also provide Partners code to include a custom search of their Archive-It collections on their own websites (available here). With our 4.8 release, we are creating the option for all partners to create a custom URL of their choosing.
In light of these improvements and the fact that few partners have utilized the Templates feature, we will no longer be supporting this tool.
We hope to continue improving the Archive-It.org public site as well as supporting partners as they create custom landing pages on their own websites (for examples of partner landing pages, see this page). We welcome any feedback or questions related to the Templates feature, or suggestions for ways to improve Archive-It.org homepages.
Comments
0 comments
Please sign in to leave a comment.