
![]()
Archive-It web archiving software upgraded to version 7.0 in January 2020. This release includes significant upgrades to web crawling, archival replay, A/V, and data management tools. Read the summaries and follow the links to documentation below in order to learn more about each of this release's updates and improvements.
Table of contents:
Crawling
De-duplication updates
Beginning with this release, all data collected by Archive-It partners de-duplicates at the seed rather than at the collection level. This simplifies the retrieval of WARC data related to individual seeds, an important step towards realizing Archive-It partners’ goal to move seeds between different collections. To increase budget efficiency, data now also de-duplicates between captures created with the “standard” and Brozzler capture technologies. Read our help guide on data de-duplication for more information.
youtube-dl for all crawls
Archive-It’s “standard” technology for web crawling--the Heritrix crawler and Umbra browser-based tool--now also includes the youtube-dl utility for more complete capture of audio and video files. Like the browser-based capture technology Brozzler, standard crawling technology now runs youtube-dl to archive the A/V components of every page archived in the course of a web crawl.
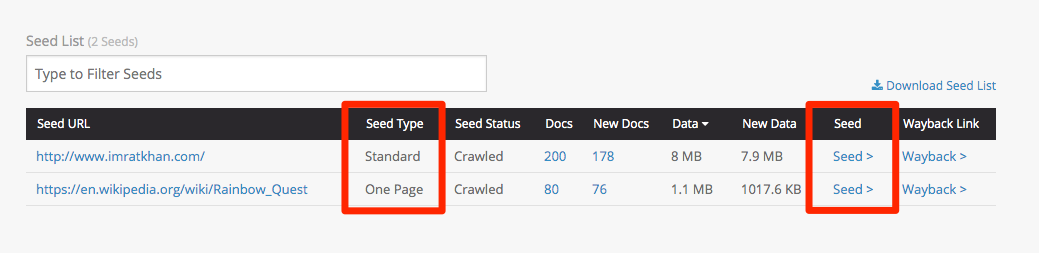
Seed information in crawl reports
Crawl reports now include each crawled seed’s type and a link to further information. Look under the seeds tab in order to see which type was assigned to each seed at the time of crawling, and to review or edit any other seed settings:
Wayback replay
OutbackCDX
Beginning with this release, Wayback indexes for Archive-It collections are served by OutbackCDX. The OutbackCDX server builds and updates indexes for partners’ collections more quickly and consistently than Archive-It’s legacy server, making content available through the Wayback interface in a more timely manner. For more information about retrieving data from this server directly, see our help guide to Wayback’s CDX/C API.
URL canonicalization
The above change to Archive-It’s capture index server also includes improvements to how Wayback retrieves and displays URLs that are generated dynamically for customized or personalized content -- a common challenge to archiving social media feeds and other interactive sites. The Wayback server now applies “fuzzy matching” rules adapted from the Webrecorder project’s pywb replay tool for more automated canonicalization and retrieval of these URLs where manual fixes had been required. In many cases this improves the speed at which sites like Facebook replay, as well as the overall accuracy.
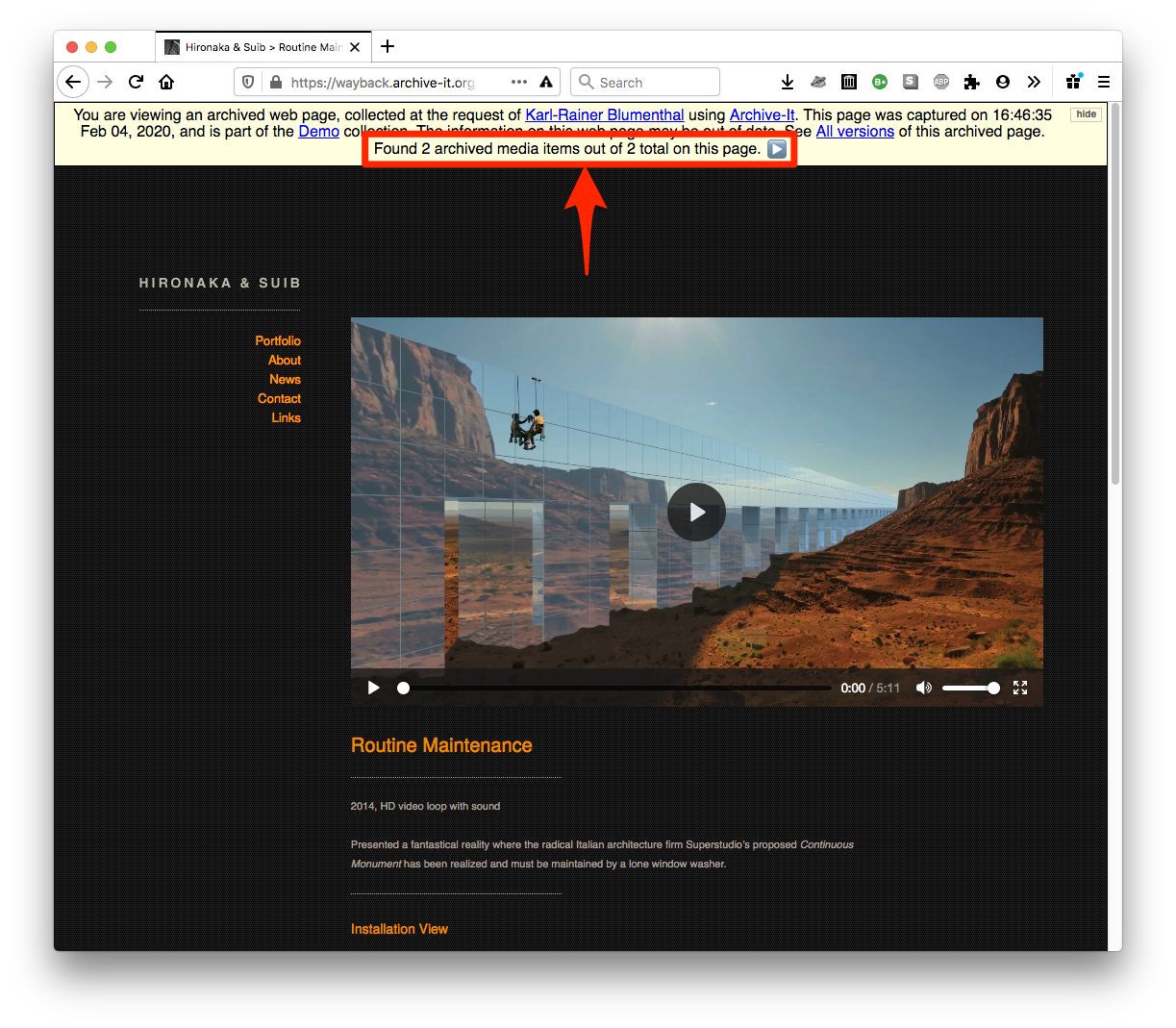
Video player
Archive-It 7.0’s Wayback replay tool includes improved audio and video playback mechanisms. Embedded media are retrieved for replay directly from crawl report data managed in Archive-It’s trough database, no longer updated periodically by metadata from a separate server. An overlayed lightbox viewer replaces the Wayback banner’s “Videos” link to multiple time-based media files embedded on the same page:
Partner API
New crawl data tables
The Archive-It Partner API now includes two new data tables to support the above crawling improvements and more detailed information retrieval by partners, on demand and outside of the Archive-It web application. They are (requires login):
- /crawl_config_snapshot - The most comprehensive details about each web crawl, including seeds and their types, frequencies, crawl limits, and scoping rules. It supersedes the “crawl_info_json” table used for Archive-It 6.0.
- /crawl_job_run - Data logged during each “run” of a single web crawl, such as before and after a manual resumption, including data and document counts, time elapsed, and end status. It supersedes the “crawl_job_resumption” table used for Archive-It 6.0.
Ongoing and future development
Consult the development roadmap here for information about Archive-It's next steps and new features as they are released. And never hesitate to share your ideas in the Feature Requests forum (requires login).
Comments
0 comments
Please sign in to leave a comment.