
![]()
The Internet Archive has continued to develop and release new Archive-It web application features and related software tools since the full January 2016 release of Archive-It version 5.0. Culminating in its new database management system for partner data in October 2018, Archive-It officially upgraded to version 6.0. Read the summaries and follow the links to complete documentation below in order to learn more about each of this release's updates and improvements.
Features and enhancements:
Capture
Automatic scoping rules
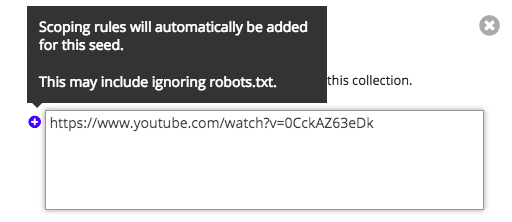
Partners may now automatically apply the latest scoping recommendations and updates to select seeds as they add them to collections and any time thereafter. For a complete list of the seed sites with automatic scoping rules and directions for applying or editing them, see: Sites with automated scoping rules. This improvement builds upon a refactoring of scoping rules that simplified their presentation in the web application as a single drop-down menu of options and will enable further bulk scoping actions (see Ongoing and Future Development).
Instant captures
The new InstaCrawl feature enables partners to add seeds to new or existing collections and immediately start crawls directly from the home page of the web application. The new Archive This! bookmarklet uses this feature to add any URL currently being viewed to one of these new crawls.
Brozzler
![]()
Brozzler is Archive-It's next generation capture technology for automated browser-based web archiving. It is a high fidelity capture tool for websites that may otherwise not be straightforward to archive due to extensive interactive features, media richness, or other challenges to traditional web crawlers. Partners may contact Archive-It's web archivists to enable Brozzler in their accounts when they have use cases for the new tool. See the short training video Introduction to Brozzler to learn much more about Brozzler's development and key use cases, and read How and when to use Brozzler in order to learn more.
Custom user agents
Partners may now request the ability to customize the Archive-It capture technologies' "user agent string" at the account or collection level. User agent strings identify the tool to live web servers in the process of web archiving and may be used to share information about partners and their archives with the web servers' administrators. Contact Archive-It's web archivists if you would like to use this new feature or read Using a Custom User Agent to learn more.
Collection management
W/ARC Uploader

Partners can now integrate existing W/ARC files into their Archive-It collections. Whether created by other or legacy capture tools, received from a donor or curator, these files can be stored, preserved, and even indexed for Wayback replay and search just like data collected with Archive-It’s capture technologies. Partners with external W/ARC files to add to their Archive-It collections may request access to this new tool in their accounts and follow the instructions provided here: Integrate external W/ARC files into Archive-It collections.
Proxy mode add-on for Firefox Quantum
Archive-It’s one-click button for toggling between "live" Wayback and Proxy modes has been fully updated for the Firefox web browser, version 49 and above, Firefox "Quantum." For instructions on installing and using the updated feature, see: Archive-It's Proxy Mode Toggle Add-On for Firefox.
Access
Elasticsearch
Internet Archive engineers have upgraded Archive-It’s full-text search software to Elasticsearch. This release enhances the search experience for patrons and partners by producing faster results, improved relevancy ranking, and stronger reliability when searching the full-text index of archived web pages. And since this is an infrastructural change, partners who use them will see the same improvements immediately through their custom search portals or OpenSearch API queries. To learn more about the new full-text search software, including how it determines relevancy and displays results, see: How does the full-text search engine work?
ArchivesSpace Bridge
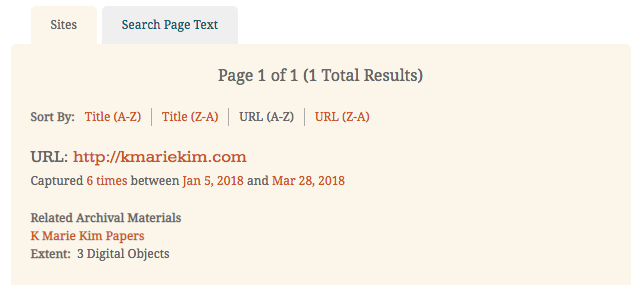
Archive-It’s "ArchivesSpace Bridge" integration enables partners to link archived websites to the related records that they create with ArchivesSpace, the open source management application for archival finding aids. It provides patrons with information about collections related to the web archives on archive-it.org directly from ArchivesSpace. To learn more about the technology and its first use case, read the announcement: New ArchivesSpace Integration.
Access Wayback captures by API
Anyone may now access Archive-It’s Wayback index using its "CDX/C" API. This API provides a new access point to the index of all web captures recorded by Archive-It partners at the document level, and queryable by collection, providing plain text information about each new record as it is added to a collection. To learn more about how this tool can be applied to enhance access layers, quality assurance, and other explorations into web archives, see the announcement: How (and why) to use Wayback's back-end index.
Private collection pages
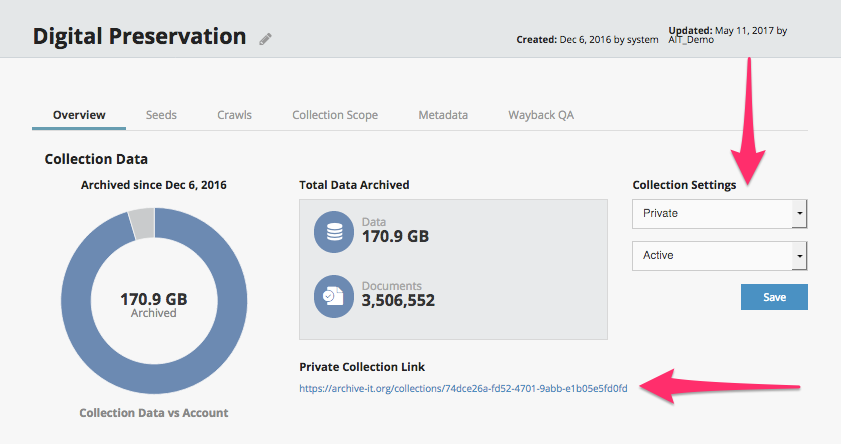
Archive-It partners can now create and share "private" collections at access points separate from the publicly listed collections at archive-it.org. This enhancement provides a quick and easy way to create access points outside of the Archive-It web application to "dark archives" of institutional content not for general public consumption, or to materials temporarily embargoed in accordance with a deed of gift. Private collection pages enable their users to browse and search like they would any public collection and so may be shared with donors or other key stakeholders without exposing collections to the general public. For more information see: How to provide access to a private collection.
Under the hood
Database
Archive-It upgraded the database management system that stores information about partners and their collections from MySQL to PostgreSQL in October 2018. The new system supports faster and more sophisticated querying of partner data by the Archive-It web application, on archive-it.org, and wherever partners may develop their own front-end access points to collection information via API. Archive-It is still developing and documenting its Partner Data API in order to facilitate more and new kinds of access to accounts' and collections' descriptive and technical metadata, so please contact the web archivist team if you have use cases you would like to see supported.
Per-seed WARC writing
As of September 2018, all Archive-It crawls write their archived data to WARC files that are specific to their particular seed URLs; data archived from any source seed are archived in WARC files separate from those of any other source seed. For information about matching seeds' unique identifying IDs to their corresponding WARC files in storage, see: WARC Naming Conventions. This enhancement is a significant development towards future collection management capabilities, such as the ability to move archived seed contents among Archive-It collections (see Ongoing and Future Development).
Reports data management
Internet Archive engineers developed Trough to improve the performance of the many post-crawl reports enabled by Archive-It's upgrade to version 5.0. The new system was custom-built to support the increased scale of reports data querying options, providing more reliable access to realtime data in currently running crawl reports and to complete data in recently completed crawl reports. For more details about areas of improvement, see the announcement: Archive-It crawl report system updates.
Ongoing and future development
Consult the development roadmap here for information about Archive-It's next steps and new features as they are released.
Comments
0 comments
Please sign in to leave a comment.