
List of Features and Updates:
All Metadata Fields are now Repeatable
Starting with this release, all metadata fields (both standard and custom) will be repeatable at the collection, seed and document levels. Previously, the only standard metadata field that was repeatable (i.e. you could add multiple values for one field) was the 'Subject' field.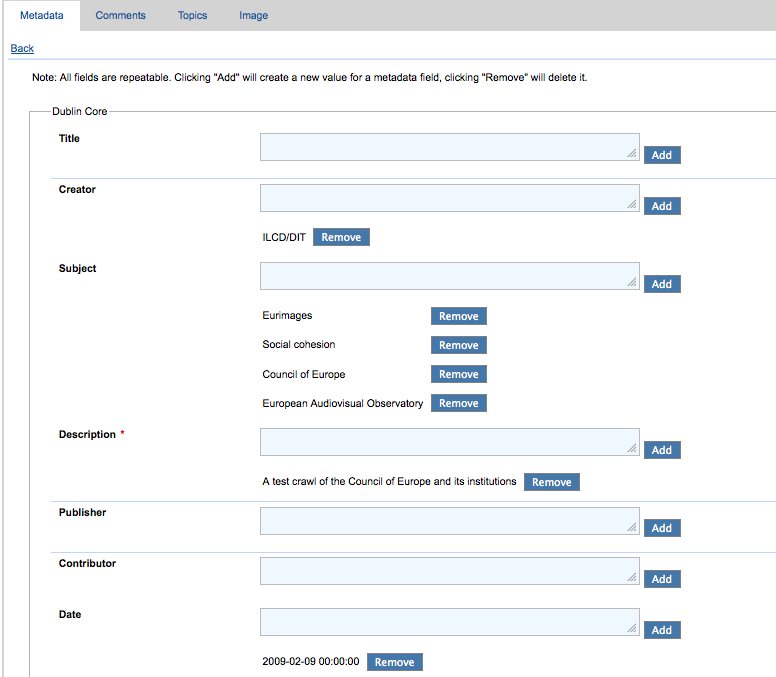
Now, by entering a value and clicking "Add" you can create a new value for that metadata field. Clicking "Remove" for a value will delete it.
You will still be able to add metadata to a number seeds at once using the "Bulk Edit" function. This will add new values for the selected fields, not replace or delete existing metadata.
On the public site, multiple metadata values for a given field will appear in a comma separated list:

Please Note: For a short time following this 4.6 release (1-2 days), the XML feed and OAI-PMH feed will be temporarily unavailable while we update it to integrate with this new repeatable metadata system.
User controls to make collections public or private
Users will now be able to directly control whether or not a collection is publicly listed or not. Previously, this was something you had to request that the Archive-It team do for you. To change the public/private status of your collection, go to the Collection Management for your collection. In the top right corner, below the collection name (see image below), there is a checkbox labeled 'Publicly Visible?'. Please allow up to 20 minutes for this change to be reflected on www.archive-it.org.
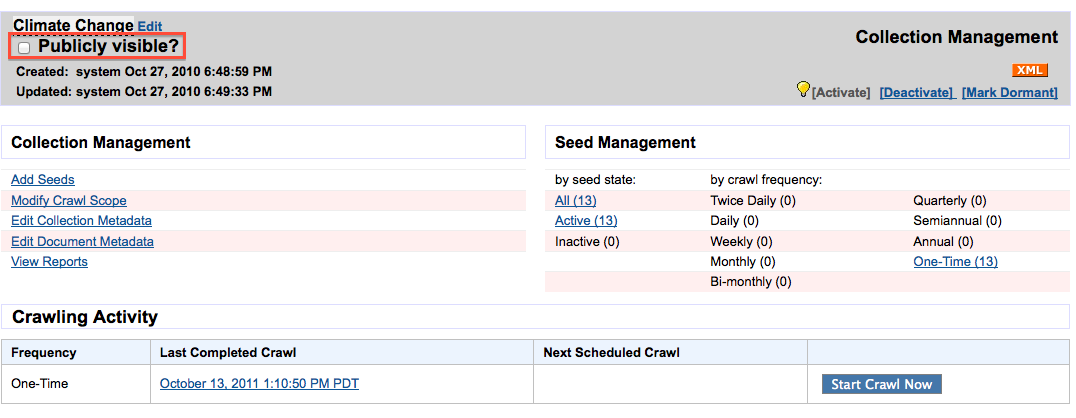
If the box is checked, your collection will be publicly listed and visible. Collections are publicly listed by default. If you uncheck this box, then your collection page will be private (meaning it is not listed anywhere on www.archive-it.org, and your collections can not be browsed or searched). Note: Even if your collection is private, you can still browse and search your content when logged into your Archive-It account. The archived pages themselves are also accessible if you send someone the exact url to view them.
New 'Limited User' Role for your supporting staff members
This new feature allows a new level of user access to help manage your account. This new type of user role are intended for use by staff members who may not be fully trained in using Archive-It and/or you do not wish to grant full access to the account. This type of user will be able to add/edit metadata, view reports, access archived content, and view collection/seed settings. They will not be able to add/edit seed or collection settings, activate or deactivate collections or seeds, modify crawl scope, or start or stop crawls. Many partners have requested this type of user level so other staff (grad students, interns, etc.) can help add metadata or perform quality assurance on crawls without having to worry about the user inadvertently making changes to other areas of the account. For your existing logins, any that had Administrator role privileges will be an Administrator, and all other logins will be 'Standard Users'. If you'd like to change the role for any user logins in your account, Administrators can make these changes in the Admin area of your account. If you are not sure who has Administrator privileges for your account, please Submit a Question to the Archive-It team and we'll be happy to help.
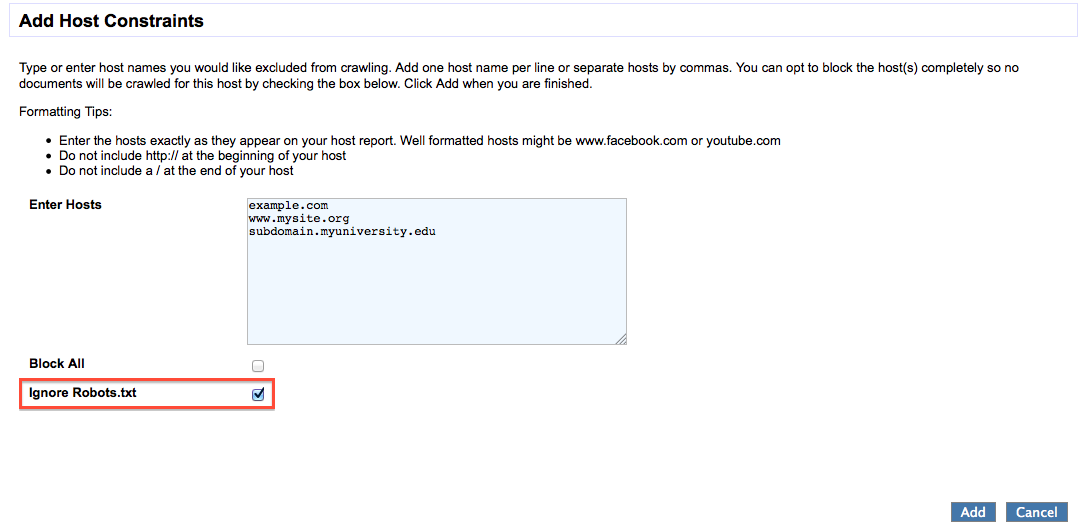
Easier to ignore robots.txt files in bulk
There will be an improved way to specify that you'd like to ignore robots.txt blocks on multiple sites at once. Currently you'd need to specify this one at a time for each site. To use this improvement, when you are adding hosts to the Host Constraints area, there is now a check box to select 'Ignore Robots.txt' for all the hosts you are adding (see below screen shot). Your account must have the option enabled that allows you to ignore robots.txt if desired.
How to Download all the PDF files archived in a crawl
Many partners have requested the ability to download just the PDF files captured in a crawl. This is something partners will now be able to do using an external tool and this documentation. This is a follow-up improvement to the updates we announced in March that provides an easier way to download all your archived data.
Comments
0 comments
Please sign in to leave a comment.