
October 20, 2009
New Features in 3.2
Document Metadata
Archive-It partners are now able to add metadata on a per-document (URL) basis. Until now, metadata could only be added at either the collection level or seed level. With this new feature, you may add any of the Dublin Core Metadata elements to any document in your collections. As this is a brand new feature, please be sure to share any feedback (positive or negative) with the Archive-It team.
Important things to know about Document Metadata:
- Document metadata utilizes the same Dublin Core Elements set used for collection and seed level metadata
- Document metadata can be attached to either:
- all capture dates for a specified url
- a specific capture date for a specified url
How to Add Document Metadata
There are two ways you are able to add metadata at a document level:
- From within the Archive-It application
- By browsing your collections in the Wayback interface
Adding Document Metadata from the Archive-It application:
From the Collection Management page for the collection you would like to add document metadata to: click the 'Edit Document Metadata' link in the left-hand column.
Enter the URL you would like to add metadata to in the upper text box, and click 'Add'.
The URL you enter can be in one of the following formats:
- Live URL (i.e. http://www.sfcentennial.com) - metadata will be associated with ALL capture dates for this document
- Archival URL (i.e. http://wayback.archive-it.org/298/20060418015343/http://www.sfcentennial.org/) - metadata will be associated with one specific capture date
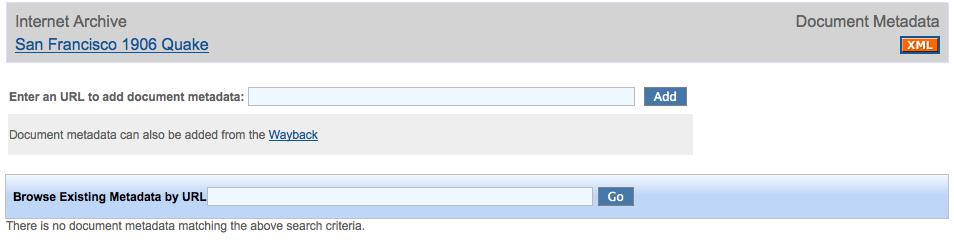
After clicking 'Add', you will be able to input any desired metadata. The same fields are available for document metadata as are available for metadata at the collection and seed levels.
Adding Document Metadata from the Wayback Interface:
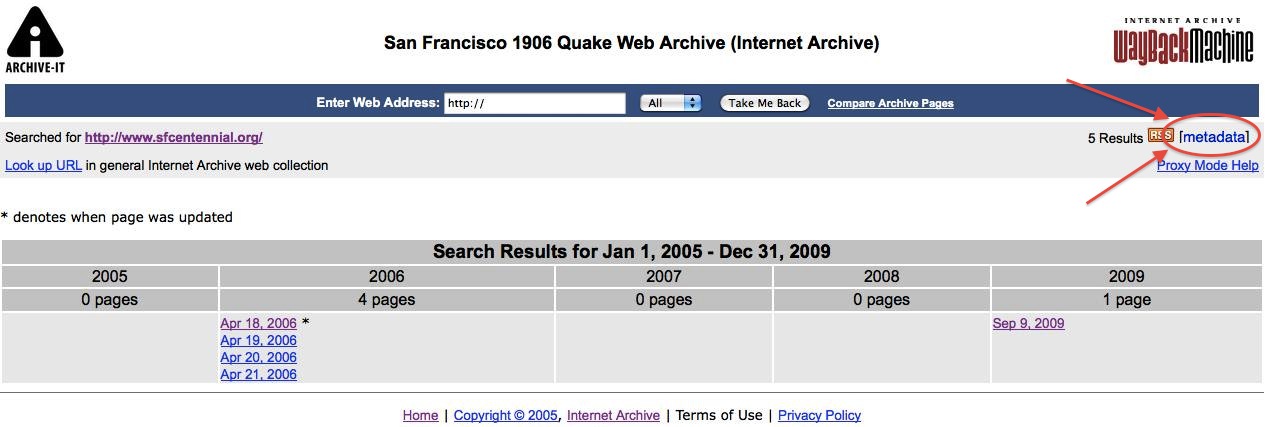
You are also able to add metadata to specific urls when browsing your archived content. If you are logged into your Archive-It account, when viewing an archived page, you will be able to see a [Metadata] link in the Archive-It banner of the archived page (the metadata link is on the right side of the banner). Clicking this link will load the Archive-It application with the URL of the archived page. You will then be taken to a page where you can enter the metadata for that page.

There is also a [Metadata] link on the Wayback calendar page, which lists and links to all capture dates for a given document. This link is in the upper right corner of the calendar page, and will take you to the Archive-It area for entering document metadata. Metadata added this way will be associated with ALL capture dates for a document.
Managing Document Level Metadata
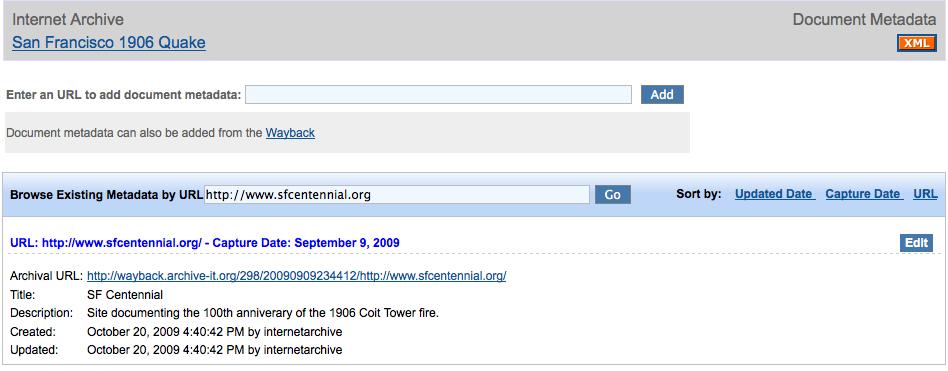
To access document metadata click the "edit document metadata" link on the collection management page. On the Document Metadata page, use the lower search box to browse and manage your document metadata after it has been created.
How to view all document level metadata in your collection:
Leave the lower search box blank, and click 'Go'. This will show a list of all existing document metadata entries. You can then click on the entry you would like to view and/or edit.

How to view document level metadata for a specific url:
Enter an exact or partial 'live' URL (the URL you would see on the live web, not the archival version). This will filter all existing document metadata entries to show only those containing the text you entered. For instance, if you enter 'archive.org', it will return any url that contains 'archive.org'. If you enter '.pdf', it will return any document with '.pdf' in the url.
How to edit document level metadata:
Find the metadata entry you would like to edit using the search box as described above. Click on the listing you would like to edit. This will take to you to a screen that allows you to view the metadata for this document. At the top of the screen click the 'Edit' button, which will allow you to change or add new metadata for this document.
Exporting Document Level Metadata
As with metadata at the collection and seed levels, you are able to export your document metadata in an XML feed. The document metadata is included in the XML feeds that can be found on your Home screen of Archive-It, as well as on your Collection Management page. You can also get a feed of ONLY document metadata for your collection by clicking on the XML button on the Document Metadata page.
Ability to crawl FTP sites
With Archive-It 3.2, partners are now able to archive FTP sites. As with anything captured using Archive-It, the content on these FTP sites must be publicly accessible (i.e. no password or login required).
To specify an FTP site, simply enter the URL of the site as a seed in your collection, just as you would set up a seed for any other site to be crawled.
Reporting Updates
PDF Report
Archive-It 3.2 contains a new report that will allow you to easily view all the PDF files that were captured in your crawl. This report can be accessed in the Reports area, under the 'PDF Report' tab. Clicking on the URL link will download the version of the PDF file archived in the crawl for which you are viewing the report. To see versions of the file for all capture dates, click on the [View All Captures] link.
Note: The PDF Report will only be available for crawls started after the Archive-It 3.2 release (October 20, 2009). Crawls started prior to this will show a blank PDF Report.

Host Report - new 'Changes' statistics
The Host Report now contains information on documents newly discovered during a crawl. A 'New document' means that the document had not been previously crawled, or had changed since the previous crawl.
Note: The 'New URLs' and 'New Bytes' columns will only be available for crawls started after the Archive-It 3.2 release (October 20, 2009). Those two columns will be blank in any crawls started prior to this date.
Crawling Updates
Crawl Limits: Updated interface for all crawl limits, New ability to limit by data
All crawl limits are now set from the same page in Archive-It. From the Collection Management page, click 'Modify Crawl Scope'. The first tab is the 'Crawl Limits' tab.
Here you are able to set limits on the number of documents captured for each crawl frequency. This is the same functionality as in previous versions of Archive-It.
You are also able to modify maximum crawl duration times for various crawl frequencies. The options to choose from are the same as they have previously been.
With this release, you are now able to set a limit on the maximum amount of data archived for each crawl frequency. Please note that partners will need to add data limits in megabytes. There are 1024 megabytes in one gigabyte.

New ‘Twice Daily’ crawl frequency and extended Quarterly crawls
We have added a new option for your crawl frequencies.
You may now choose 'Twice Daily' for content you need to capture more frequently than once a day. Twice daily crawls will restart every 12 hours. Please be careful when using this option so that you do not use up too much of your document or data budget. The Archive-It team strongly recommends running test crawls on seeds before scheduling them to the twice daily frequency.
Additionally, you are now able to choose a 7 day duration for Quarterly crawls, along with the existing options of 3 or 5 days.
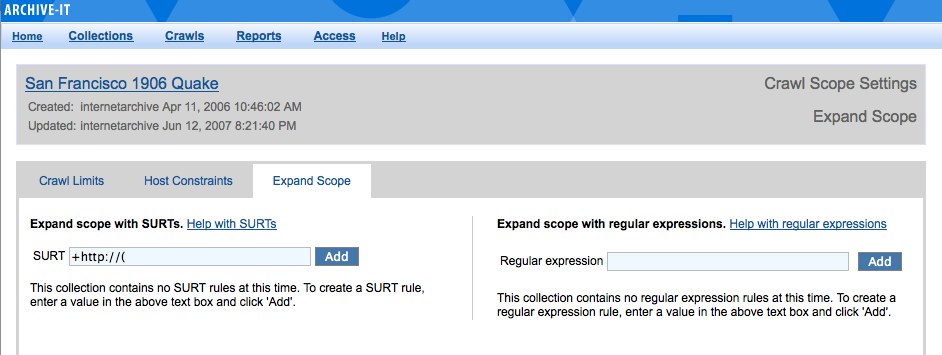
Scoping: using a regular expression to expand your scope
Under the "modify crawl scope" settings, partners will find an expand scope tab. On this tab, partners can now add regular expressions, in addition to using scope rules (SURTs) that will allow partners to archive content that would not normally be in scope. To add a regular expression, partners should enter the regular expression and click "add".
Access Updates
We recently updated the Archive-It banner that appears at the top of all archived pages. In addition to the information that was previously shown, the name of the institution creating the collection listed and the collection name s also a link
Another change to the disclaimer is associated with our new Document Metadata feature. If a partner has input document metadata for a given account, a [Metadata] link will appear at the end of the dislaimer text. Clicking on this will allow users to view the metadata associated with this document. If you are a logged in user, you will always see the [Metadata] link when viewing your archived pages, as this allows you direct, easy access to add metadata to the document, while browsing your collection.
Comments
0 comments
Please sign in to leave a comment.