
New User Interface
-Archive-Its new user interface has eliminated all right side navigation links. Instead all navigation is found along the top of the screen. All collection building and management is reachable via collections drop down menus. Likewise, all information pertaining to your crawls (including reports) can be found under crawls. The Go to link is a new quick navigation feature that will take you right to your seed list for the collection that you click on. Roll your cursor over Go To to see the links.
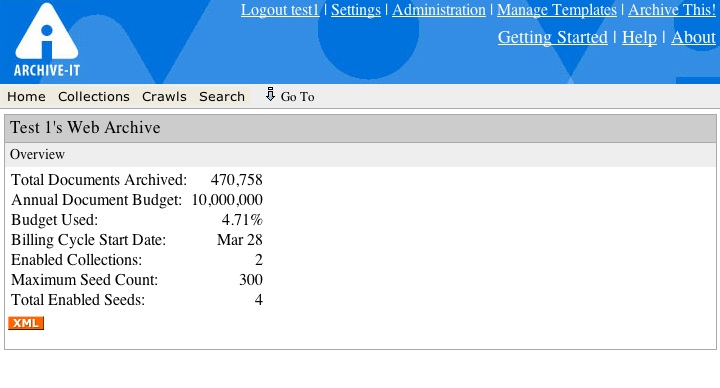
-Other navigation links are found in the upper right corner of the screen. New links like settings, manage templates, and Archive This! are new features and are explained later in these release notes. Getting started is a quick introduction for new users to the application. Help goes to the help wiki. Finally, about lists the version number of the current application, release date and the people involved with making Archive-It possible. Below is a screenshot of the new version of the overview or home view showing these changes.
Administration
-Template webpages are now available for your institution from the manage templates link. You will be able to enter your own custom content and the page will be available from a unique URL hosted on archive-it.org. This will be a great landing page for patrons of your web collections to get information about your institution, its collections, access your seed lists as well as search the collections. Please see the managing templates on the help wiki for more information.
-All users can change their passwords through the settings link. You can enter your full name and email address there as well. In the future this information will be used to send you Archive-It alerts if the application notices problems with your crawls.
Documentation
-More help documents have been added to the Archive-It Help Wiki. Wiki documents are exportable to word docs and pdfs for offline perusing. The new documents are:
-Getting Started (a guide to Archive-It for first time users)
-Managing Templates Feature Guide
-Manually Restarting Crawls Feature Guide
-Listing of reports
-1.5 Application Release Notes
-Updated versions of the previous documents
-In addition to the online help section, there is a getting started screen inside the application itself with some easy steps for new users for collecting, monitoring and searching web archives using Archive-It.
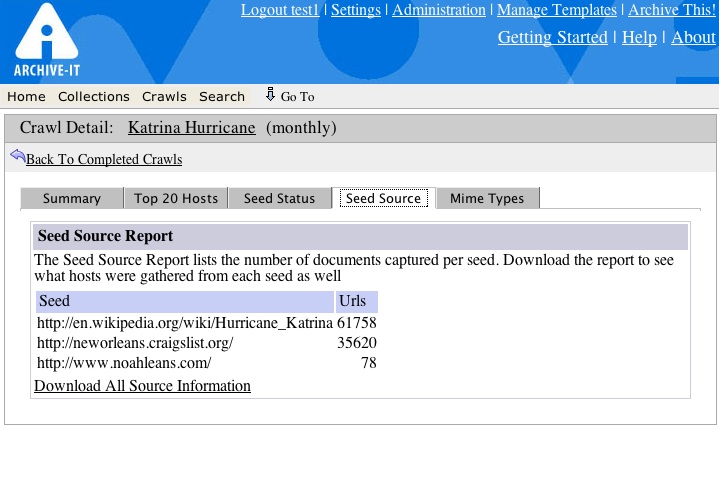
-Archive-It now has a seed source report. This report will tell you how many documents were captured from each individual seed. If you download the report it will also tell you which hosts were archived as a result of which seed.
-Reports now download as .csv files which can be opened directly with Excel. The reports also now all have easily identifiable filenames: host report is host.csv, seed status is seed.csv, seed source report is seed.csv and mime report downloads as mimetype.csv.
Partner Community
-The archiveitmembers@archive.org mailing list will now be a list serve. Instructions will be mailed out to all subscribers for accessing the mailing list archives online. This list can be used for Archive-It questions and support as well as discussion for how different institutions are using the service.
-Coming in July (with the 2.0 release), there will be a blog and bulletin board just for Archive-It partners. This will be a web page on archiveit.org.
Collections
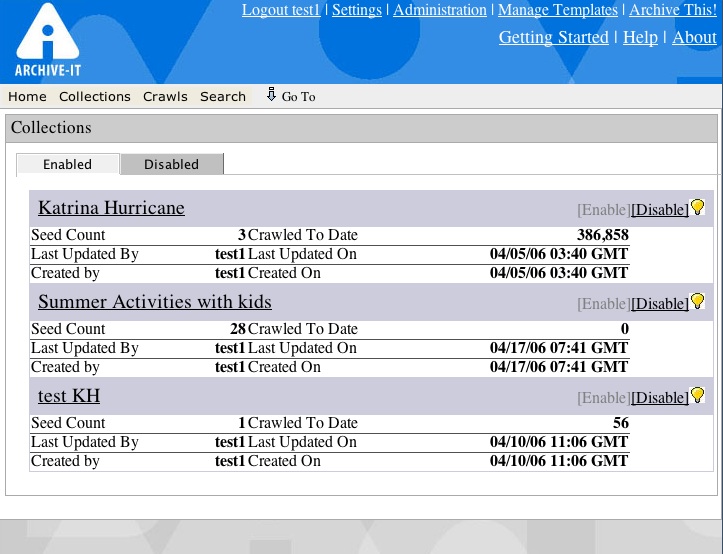
-As mentioned earlier, accessing and creating collections as well as managing seeds is found under the collections drop down menu. Under view collections, you will see all your enabled and disabled collections separated by tabs for easy browsing.
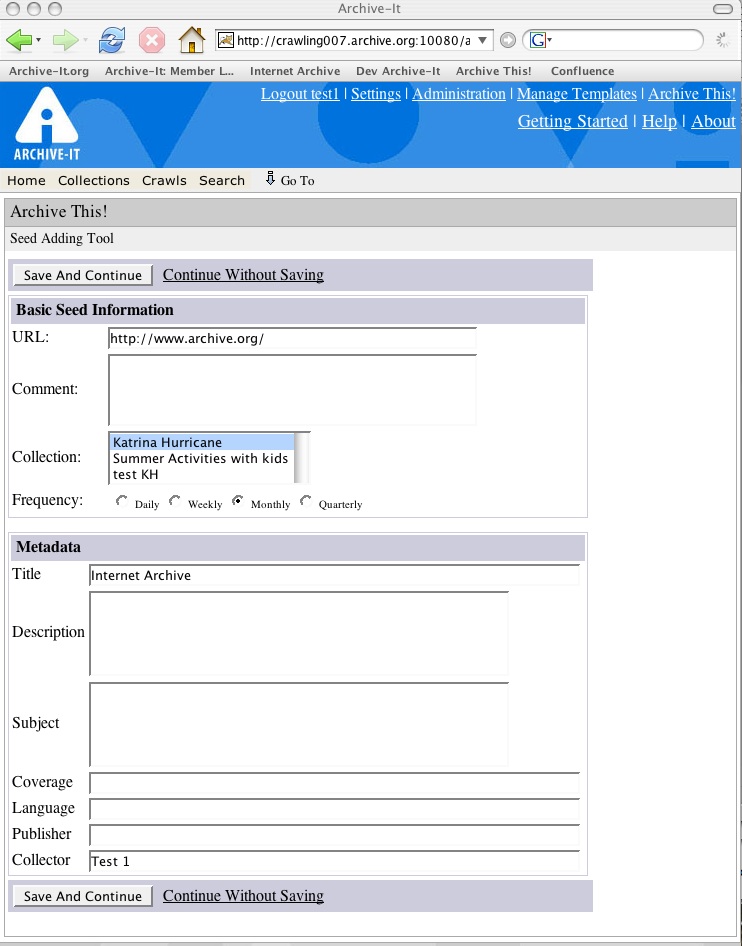
-Archive-It has a brand new collection development tool called Archive This! It is a bookmarklet that goes onto your web browser's bookmarks bar. Right click on the Archive This! link in the upper right hand side of your screen and select to add it to your bookmarks bar (in some browser's you can drag it right onto the browser bar). When you are surfing the Internet and find a site you want to add to your collection, click the Archive This! button. The Archive-It application will open and you can instantly assign the seed to a collection, add metadata and set the frequency. The seed will now be scheduled with your crawl.
-Creating a new collection is the same process it has been. The only difference here is that when you enter the name of the collection, you will also need to designate a unique collection identifier. This should be an abbreviated version of your collection name with a maximum of10 uppercase characters (no spaces or numbers). The identifier is added to the metadata of all arc files (the format archived webpages are stored in) for easy identification purposes in our database.
-Exporting your seed and collection metadata to your Institution's catalogs is now possible. We have two kinds of XML feeds for you to use. One is accessible from the home view of the application. Click this XML button (lower left side of screen) to get metadata for all your seeds and all collections in one feed.
There is also an XML button on the seed list view (upper right) of each of your collections. If you click this XML button, you will only get metadata from the collection you are currently viewing. You can turn off and on the XML feature from the administration screen.
-All 15 fields of the Dublin Core Metadata Element set are available for use in cataloging at the seed and collection level. In addition to the standard 15, Archive-It includes a collector field and an area for your comments.
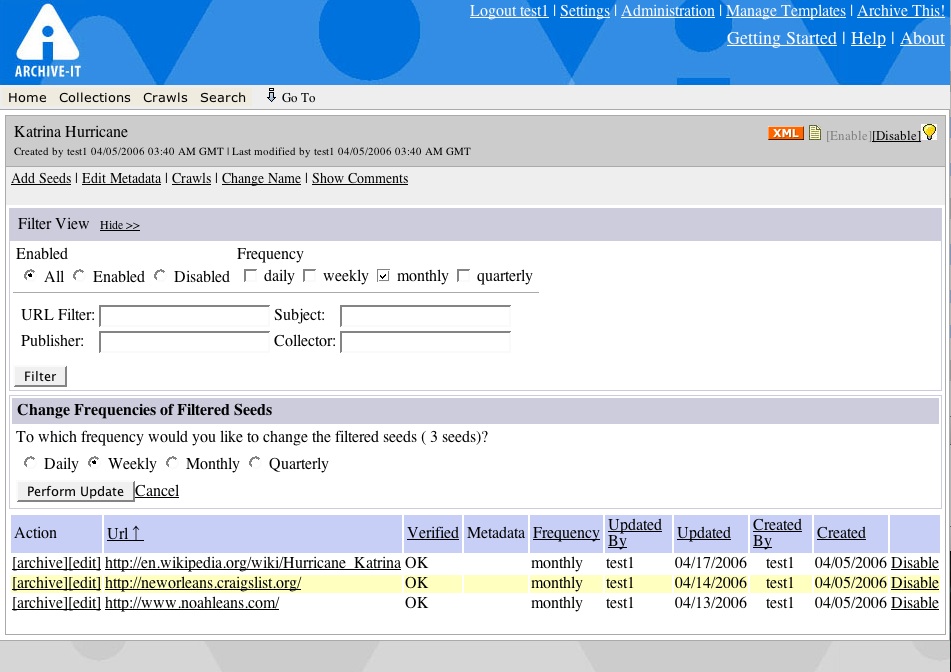
-You can now make bulk changes to your seed frequencies on the seed list view in any of your collections. Using the seed filter, set up a filter of frequencies that you want to change (for example if you want to change all your weekly seeds to monthly, filter the weekly ones). Once you have the seeds you want to change filtered, click on the "change frequencies of filtered seeds" link and a box will open with some choices. Click on the frequency you want to change those seeds to and click "perform update". The seeds you filtered will now all have the new frequency assigned to them.
Crawls
-All information pertaining to current crawls, crawl reports and scheduled crawls can be found under the crawls drop down menu. Each of these three views are again separated by tabs for easy navigation and appearance.
View current will show you crawls that are running at the moment. Collections listed here as "on deck" are past their schedule start date and time, but a crawler has not been allocated to them yet. This would only happen if demand for crawlers was particularly high; collections should not remain on deck for more than a few hours.
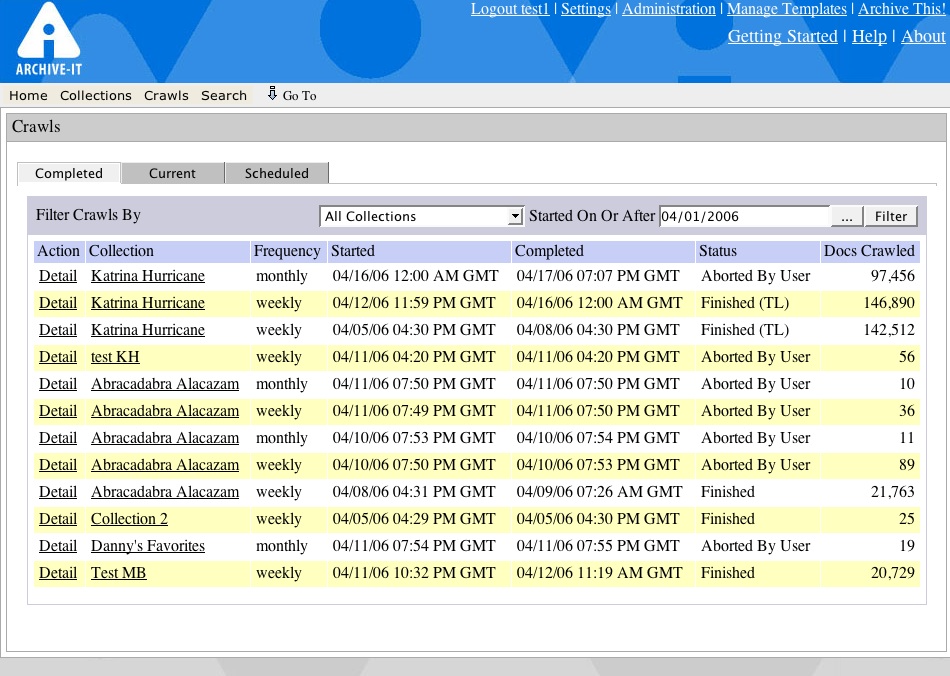
View completed shows you crawls that have finished running. Click on the detail button to the left of the collection name to access all reports.
View scheduled displays start dates and times for your crawls by frequency. You will see a specified date and time for each frequency you have seeds set to within your collections.
-In this release the Archive-It team has developed a few manual crawl operation features. If you would like to stop a crawl while it is running go to crawls --> view current and click stop. This will immediately end your crawl, but another crawl will not begin again until scheduled.
-If you do not want to wait for a scheduled crawl to start, go to crawls --> manually start crawlers. From here you can identify which seeds based on their frequency you want immediately re-crawled. This feature will not reassign or override the seed frequencies you have already assigned. The crawls you choose to restart will also be rescheduled based on the restart date (if you restart a quarterly crawl, that crawl will not occur for 3 months after the restart date). There is an entire help document dedicated to this feature on the help wiki to assist you further.
Access
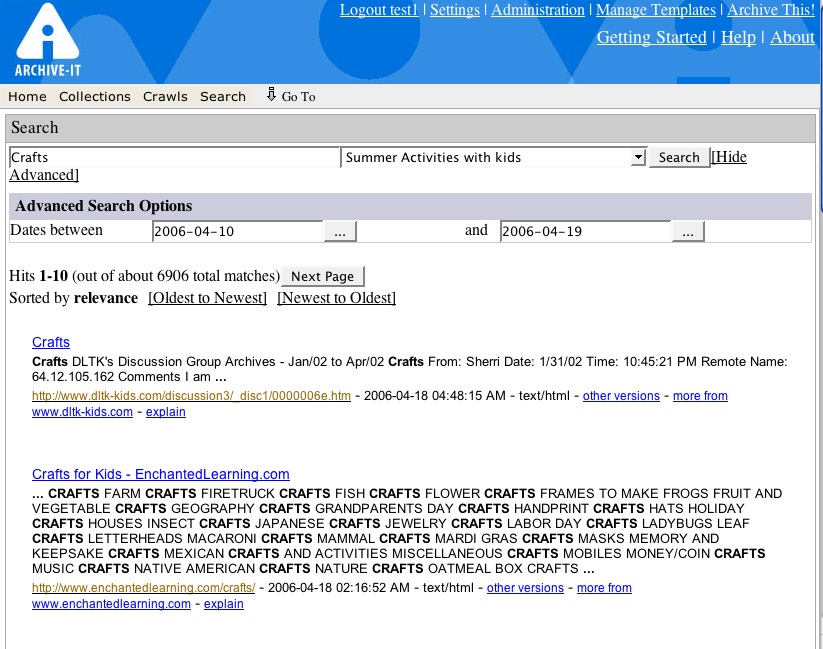
-Search results can now be sorted by date and date range. From inside the application, click on search and enter a search term as you have before. To sort your results by date range, click advanced and use the calendar (push the button to the right of the empty date field) to select your date range or enter dates manually as yyyy-mm-dd.
Comments
0 comments
Please sign in to leave a comment.