
Interested in getting to know Archive-It better? Here is some introductory information to help you get started:
- Introduction to Archive-It
- Subscription FAQ
- How does Archive-It work?
- Basic Terminology
- Account Structure
- How the crawler knows what to capture
- What an archived page can and cannot do
- Archive-It support
Introduction to Archive-It
Archive-It is a curator-controlled web archiving service, that crawls, hosts, and provides access to web-based content, including video and social media.
All Archive-It subscriptions are for one year, are renewable, and include:
- Web Application training for all users, as well as continued partner support, technical assistance, and advanced trainings
- Scoping tools to expand or limit the extent of the crawl and content
- Metadata cataloging fields at the collection, website and document level
- Ability to capture content using ten (10) different frequencies
- Downloadable crawl reports, plus Quality Assurance and reporting tools
- Content publicly available for viewing 24 hours after the content has been captured
- Restricted access options available for archived content and collections
- Hosting of the data, online access, and two copies stored (a primary and a back-up copy) in perpetuity
- Full text search of the collections: basic and advanced options + metadata search
- Ability to download archived files at any time from our servers
- No additional fees for hosting, software update, maintenance or new releases
Subscription FAQ
Q: When do subscriptions start?
A: Subscriptions are annual, renewable, and can start on the 1st or 15th of any month.
Q: How are subscription levels determined?
A: Subscription levels are based on the amount of data needed to capture your target sites in a given year. Having an idea of the number and type of sites you want to capture and the frequency at which you want to capture them will help us determine an appropriate subscription level/data budget.
Q: What happens if I use all of my data budget before my subscription ends?
A: Things happen! You won't be penalized for accidentally capturing more data than you intended. If you end up needing more data than anticipated to capture everything you need, we can help you move up to the next subscription level.
Q: What happens to my archived data if my organization leaves Archive-It?
A: We never delete data! Any collections you choose to make public on Archive-It.org would remain public and any content you choose to keep private would still be accessible through direct links. You would also still have access to your WARC files if you decide to download them later. If you chose to rejoin, you could jump back into the same account.
Q: Do I have to pay for past years of storage?
A: Subscription costs are only for the current year’s storage, however we store all of your past years data for you in perpetuity.
Q: Are there backups of data?
A: Yes, we keep two copies of all data.
Q: Do you ever delete data?
A: We never delete data for you. We do have a Test Crawl feature, where partners have the option to save or delete their own crawls.
Q: I've done some web archiving using other tools, can I include those captures in my Archive-It account?
A: Yes! Web archives in the form of WARC files can be added to an Archive-It account, however they would count against your data budget.
How does Archive-It work?
Learn more about the Archive-It approach to web archiving.
Basic Terminology
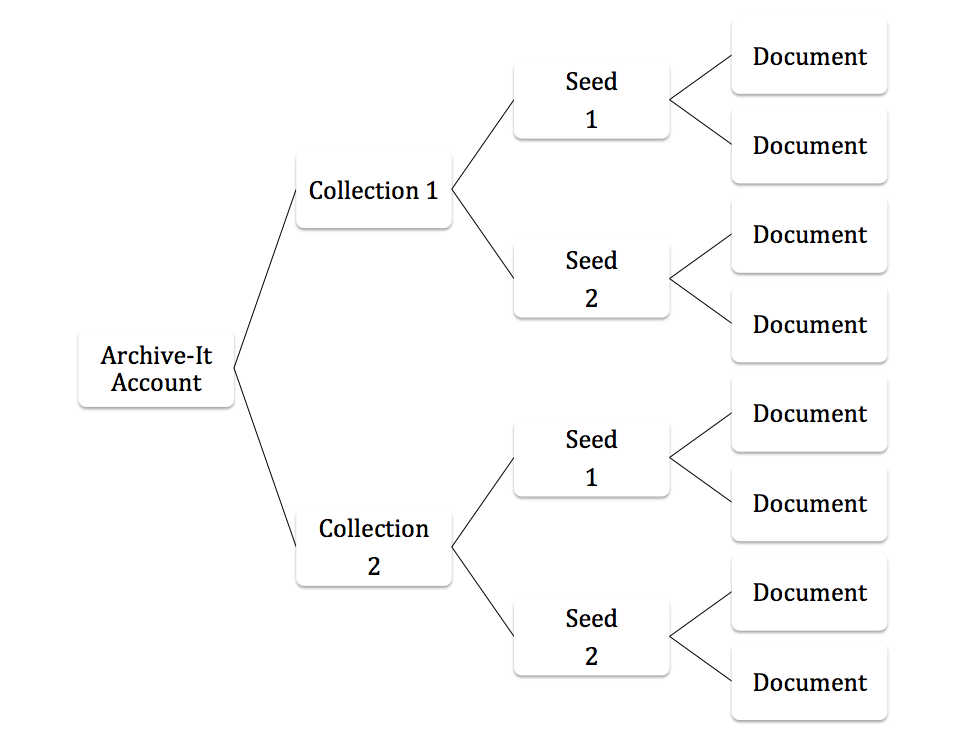
Collection: A group of seed URLs with a similar theme, topic, or domain
Seed: The starting point URL for the crawler, and the access point for users of public collections
Document: Any file with a unique URL (html, image, PDF, video etc.). Seeds are made up of multiple documents
Crawler: Software that visits websites and indexes the information on those sites
Crawl: The action that the crawler takes to go out and archive your seeds
Account Structure
Archive-It accounts are made up of Collections of Seed URLs. Those seeds are the starting point for the Crawler and the main access points for users in public collections. A seed URL points to content captured in Wayback which is made up of a number of individual URLs, called Documents. You can explore how current partners have structured collections at: https://archive-it.org
How the crawler knows what to capture
The crawler starts with the seed URLs and follow links within the seed site in order to archive pages. The way you format your seeds will help determine the scope of your crawl.
If, for instance, your seed URL is http://archive.org/, then the crawler will archive all accessible content from the host archive.org, including http://archive.org/about, https://archive.org/details/audio/, and more. Any embedded content required for these page to render properly (images, stylesheets, etc.) will be archived. Links to other sites, such as http://ca.gov, will not (by default) be archived. *If you want linked URLs archived, then they will need to be added as additional seed URLs.
Directories
If you only want to archive a specific directory of a site, you can format your seed with a / at the end to let the crawler know to only access content within that directory. For example, if you only want to crawl the "About" directory of http://archive.org, you would format your seed like this:http://archive.org/about/.
Sub-domains
Sub-domains, divisions of a larger site named to the left of the host name, as in http://crawler.archive.org, are not included by default. If there are sub-domains that you are interested in capturing, consider including some of them as seeds in your trial collection.
What an archived page can and cannot do
Archived pages should function in the same ways that they did on the live web at the time that they were archived, however some websites or types of content on them are designed in such a way that they are not easily archivable. The primary exceptions are:
Robots.txt
By default, our crawler respects robots.txt exclusion files, which webmasters can use to block crawlers like ours from accessing their websites. However, Archive-It offers the option to ignore robots.txt on a host-by-host basis. If you know that your trial sites are blocked by robots.txt, we can apply our Ignore Robots.txt feature to the blocked hosts so that they may be archived. Some larger sites like Facebook or YouTube use robots.txt blocks on their pages. In trial crawls, we will usually add Ignore Robots.txt rules for these hosts automatically. *Please let us know beforehand if you would like to respect the robots.txt blocks for these sites.
To learn more about robots.txt you, see Robots.txt exclusions and how they can impact your web archives.
Forms and search boxes
The functionality of forms and search boxes will not transfer to an archived page, however the database content is almost always accessible from another spot in the site, such as a site map or other direct links. Subscribing partners' public collections are full text searchable from the public access page on Archive-it.org
JavaScript
Most JavaScript implementations archive well, however we sometimes come across applications that are more complicated and difficult to archive. In especially challenging cases, these may require input from our engineers.
Videos
Videos typically capture and playback well, however there are some proprietary formats that are more difficult to capture and playback. Others will require additional rules to be in place before we run the crawl. YouTube videos, for example, usually capture well as embedded videos or from their respective watch or channel pages, but require additional preparation before a crawl is run. Vimeo videos are a bit more complicated; while they can be captured, they have additional requirements for capture and playback.
Archive-It support
With Archive-It, you get support so you don't have to figure out web archiving on your own! An account includes access to our Help Center, Community Forum, both new partner and ongoing training opportunities, and a team of Web Archivists.
Further information
If you have questions about the above concepts or anything else during your trial, please feel free to reach out directly to Archive-It's Web Archivists.
Comments
0 comments
Please sign in to leave a comment.