
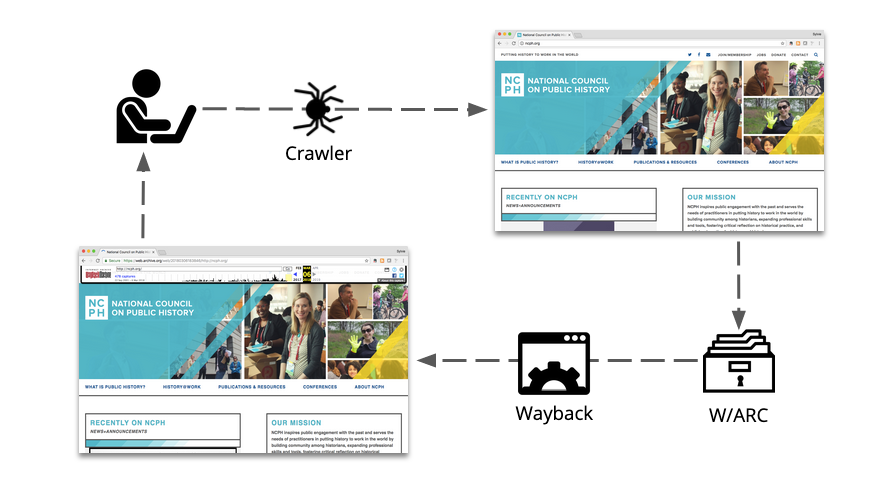
Web archiving is a series of steps that work together for an end goal: to interact with a website as it looked on the day that it was archived. There are examples of web archiving without non-replay purposes, such as data mining, but generally web archiving is a process of the separate steps of capture, storage, and replay, each using different technology.
This process starts with a person kicking off a web crawler. This crawler, or robot/bot as they are also known, goes out to the live web and gathers up all of the source material that make up that web page. This includes all of the images, text, any javascript that makes the page dynamic, any CSS that gives the site its “look and feel,” etc.
Once all of that is captured, plus a little metadata about the site (like its title), the crawler stores everything in a WARC, or web archive file. WARCs have a limit on how much they can hold, so it usually takes multiple WARCs to store a website. Unfortunately WARC files will not automatically replay on a screen when opened, but require technology to replay them. The Archive-It replay mechanism is called Wayback.
The end result of all of these steps is the page as it looked on the day it was archived.
Because web archives can be big, they benefit from description and full text search, to increase access. This is what Archive-It is: all of these steps wrapped up into one account.
Comments
0 comments
Please sign in to leave a comment.