
Release Date: July 8, 2010
Crawling - New Features
Seed Types
When adding seeds to your collections, you will now have the option of selecting one of three 'seed types' for each seed:
- Default
- Crawl One Page Only
- RSS/News Feed
The seed type you choose will determine how that specific seed URL is crawled.
The Default option will be the case for the vast majority of your seeds. This is the same option that all your seeds created prior to the 3.5 release will be set at, and there will be no changes to how crawling is done on these seeds.
The other two options 'Crawl One Page Only' and 'RSS/News Feed' are new, and are described in more detail below.
Crawling One Page Only
Selecting the 'Crawl One Page Only' option for a seed URL will mean that only the seed URL page will be captured (i.e. no links to other pages will be captured). Please note: Any embedded images or other files (such as CSS or Javascript files) that are necessary in order to accurately render the page will be captured.
Crawling RSS/News Feeds
Selecting the 'RSS/News Feed' seed type should be used when you wish to use an RSS/News feed as one of your seed URLs.
The crawler will go to each URL that is listed in the feed and will crawl just that one URL (i.e. each URL in the feed will be crawled as 'one page only')
This feature will allow you to easily archive articles on a specific topic or event of interest to you on a regular basis, without needing to find new articles manually every time.
Scoping Rules 'Made Easy'
This exciting update will enable ALL our partners to easily add scoping rules that block or include specific URLs, without having to depend on the Archive-It team to help create the 'regular expressions' or 'SURTs' that up until now have been the only way to specify specific URLs that should or should not be included in your crawls.
This update affects both the Host Constraints and the Expand Scope tabs.
This update also makes it possible to easily add multiple rules for each host in the Host Constraints area. Until now, you had to combine them all into one giant regular expression.
You will still continue to be able to enter your scoping rules as Regular Expressions or SURTs if you prefer, and any of these rules that are already in your collections will still be available and work the same as they have previously.
Archive Only PDF Files
Institutions often only want to archive the PDF files that are part of a site. With this feature, partners now have the option when crawling a site to archive only the PDF files. Please note that the entire site will be crawled but ONLY the PDF's will actually be archived and counted toward your account's document and data budgets.
This setting can currently be set to apply to specific frequencies, which is controlled on the Crawl Limits tab in the 'Modify Crawl Scope' area for each collection.
Collection/Seed Management - New Features
Customized Metadata Fields
Customized metadata fields allow institutions to enter metadata field names and corresponding values beyond the 15 Dublin Core fields provided at the collection, seed, and document level.

Grouping (Non persistent) Seed URLs
This feature will allow partners to specify seed URLs that should be grouped together . Each 'Group' will be listed together under the designated group name on your public collection listing page, along with the date range during which each URL was captured. There will also be a separate page for displaying each group.
One common use case for this can help address issues that come up when the URL for a specific site is not persistent over the years. Specifying these URLs as a 'Group' allows collection curators to identify seed URLs that should be considered the same site.
Each site group has its own unique URL as well, so if you need to provide access to a certain site group from outside Archive-It (e.g. from your institution's site), you are able to link to that site group.
Reporting - New Features
QA Report
As many partners have requested, we have introduced a new report to help users more effectively evaluate their crawls and why content on a page may not be captured or viewable. Please note: this report is currently in BETA and we welcome any feedback. Some parts of this feature are still in development and will become more robust as we continue to develop this feature. For example:This current version will check your exact seed URLs. In the future, additional URLs will be able to be QA'ed, as well as an option for a user to run a "patch" crawl to capture additional content.
To use this report, in the left-hand column, select the Seed URL you would like to QA. You will see a screenshot of the archived web page, a list of embedded files that are included in this page, and the reason(s) why there is an issue with the capture or display.
Out of Scope URL Report
This is a report to show the list of URLs that were discovered during the crawl but that were determined to be out of scope. This will be helpful in determining if a user wants to include any of these URLs in the next crawl.
Access Updates
Faster Search
We have made significant upgrades to the performance of searching within your collections, and we hope you will notice and appreciate the much faster full-text search results for you and your patrons in both basic and advanced search (in most cases).
These upgrades will positively affect all searches that are done just within one collection, or across all collections in your account. Based on partner input, we focused our energy on optimizing search for specific collections or across one partner. Searching across all Archive-It partners collections will remain slow as you are searching through over a billion pages!
OpenSearch API
If you would like to display search results for your Archive-It collection on your own institution's website, you can utilize our OpenSearch API in order to do so. While this API has actually existed previously, there have been a number of changes made in connection with the performance updates described above.
Other Changes and Enhancements You May Notice
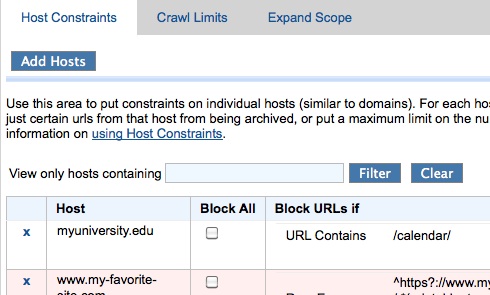
Ability to Filter Host Constraints
If you have collections with tens or hundreds of Host Constraints, you will appreciate the new ability to filter the Host Constraints page to view and edit only the hosts you are looking for.
Opening Large Queued Documents or Other Reports
Opening large Queued documents reports or other URL lists within the Host Report should now run more smoothly.
All reports over a certain size will now automatically be downloaded to a file on your computer so that they do not crash your browser when you try to open them. These downloaded reports will be zipped, so you will need to unzip them before viewing. You can then use a text editor program to view the content of these reports.
Smaller reports will continue to be opened in a new browser window as they have previously. If you would like to download one of these however, you just need to right-click the numbered link and choose the 'Save Link As' (or a similar option depending on your browser).
Edit Your Institution's Information
Partners now have the ability to edit the description and URL displayed for your institution on your institution's page on archive-it.org (for example see, the Description and URL text at the top of the page here ). Previously this was something that could only updated by the Archive-It team. To access this, go the 'Admin' area in the upper right corner of your Archive-It account (you must be an 'administrator' for your account), and then go to the 'Account Settings' area.
Comments
0 comments
Please sign in to leave a comment.