
Public Archive-It Website
Administration
Crawls
Reports
Public Archive-It Website
-The Archive-It public website will be soon be updated to include a better user interface, updated tour features and a generally cleaner appearance.
-We will be adding advanced search information to search results before October 17, 2007. By clicking "advanced search" from the top of your search results page, you will be able to easily define your search results by document, host and date.
-Included on the new public site will be Wayback Machine search boxes on each collection access page. Each partner collection has a page on the Archive-It site showing the name of the collection, collection description, seed list and a text search box, for example http://www.archive-it.org/collections/618; These pages will now also include an URL search box where patrons can search for a specific URL collection.
Administration
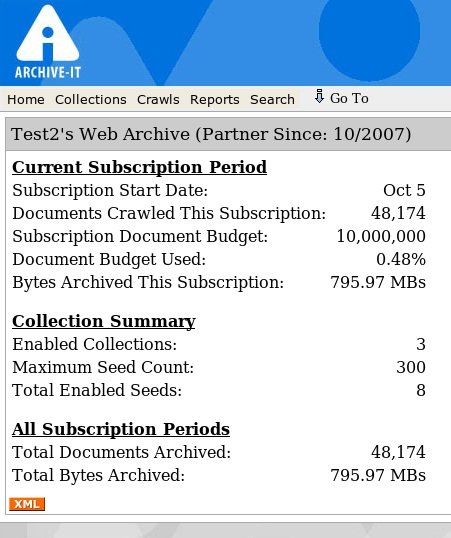
On the "home" page in the application you will now be able to see the amount of data (in mb, gb, etc) you have archived within one subscription cycle. Also shown is the cumulative total across all subscription periods. We have broken up the information so you can easily discern what information applies to current and cumulative subscription periods.
Crawls
Starting October 11, 2007 all annual crawls will crawl up to 5 days (as long as there are still documents to capture). Weekly, monthly, and quarterly crawls will continue to run up to 3 days and daily crawls will last 24 hours as they have before.
Reports
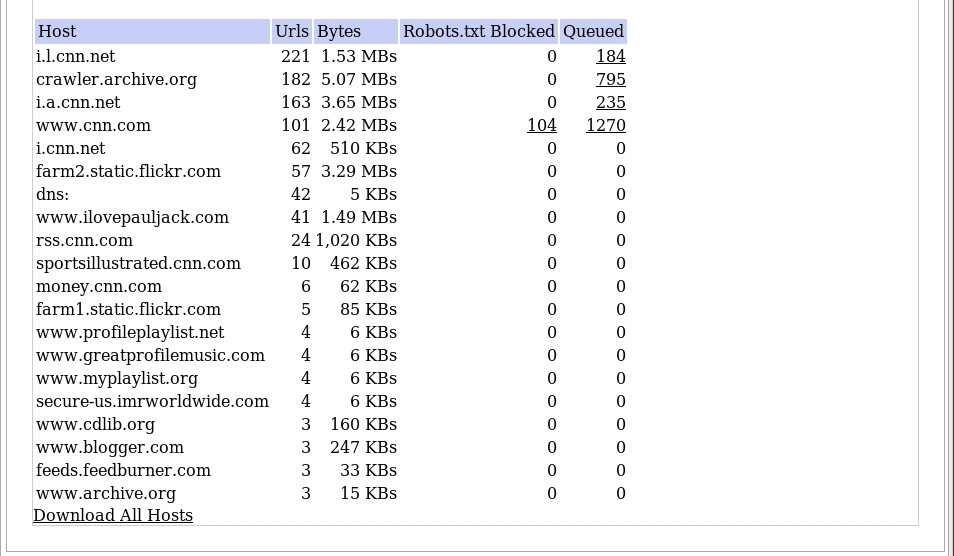
New information is now included in the hosts report for quarterly and annual crawls. We anticipate having this feature available for monthly and possibly weekly crawls in 2008. Please note that both new report features can take up to 24 hours to process after your crawl finishes.
-Robots.txt: will show the number of documents discovered but not crawled due to robots.txt exclusions for each host. You can click the number displayed to view and download the specific documents excluded.
-Queued: will show the number of documents discovered but not crawled due to the crawler's time limit. Click on the numbers to view the documents that were still in queue when the crawl ended.
Regarding documents that show up as queued, sometimes this can happen due to a crawler trap on the site you are trying to crawl. If your crawl is still timing out after a 5 day crawl or if there are badly formed urls (these could be really long with repeated directories showing), please contact partner support for assistance. In many instances a crawl trap can be avoided with some simple modifications. The Archive-It partner specialist can help you set these up.
Comments
0 comments
Please sign in to leave a comment.