
Overview
Partners can archive streaming audio and video files from the Internet Archive (archive.org) that are embedded in the pages that they collect. This guide provides an overview of how to properly format, scope, and crawl audio and video files from the Internet Archive (archive.org).
Known issues
Currently, there are no known issues with archiving audio and video files from the Internet Archive (archive.org) that are embedded in the pages that partners collect.
You can find a full list of known issues for archiving various platforms on our Status of monitored platforms page.
On this page:
How to scope your Internet Archive (archive.org) audio and video seeds
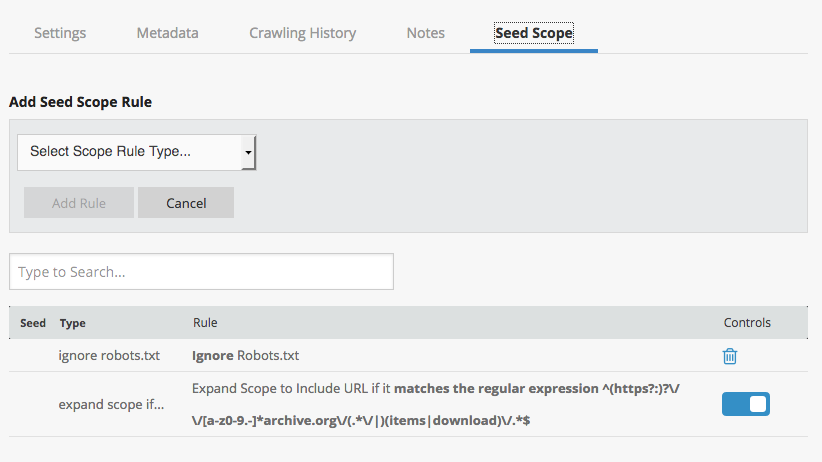
In order to capture these archive.org embeds, it is necessary to apply the following crawl scope modifications:
- Ignore robots.txt (either entirely at the seed level or on the host archive.org at the collection level)
- Expand scope to include URL if it matches the regular expression:
^(https?:)?\/\/[a-z0-9.-]*archive.org\/(.*\/|)(items|download|includes)\/.*$
With these rules in place, audio and video on captured pages should play normally.
Comments
0 comments
Please sign in to leave a comment.