Overview
Facebook is an online social media networking service. This guide provides an overview of how to properly format, scope, and crawl Facebook seeds.
Known issues
Social media platforms like Facebook can be difficult to archive. Currently, Facebook has the following issues that we continue to actively monitor:
- ⚠️ Recent captures of Facebook organizational profile pages and Groups pages resolve to a blank logo page. Prior to ~mid-April 2025, Facebook intermittently blocked crawls of organizational and Groups pages. When not blocked, Wayback replay is often limited to the top post. Feed posts, comments, and likes will not expand when clicked.
- ⚠️ Individual posts - including photos and videos - can sometimes be collected and replayed successfully.
- ⚠️ To replay, dismiss the login prompt if you can. Replay media through the Wayback banner.
You can find a full list of known issues for archiving various platforms on our Social media and other platforms status page.
On this page:
- How to select and format your Facebook seeds
- Scoping Facebook seeds
- Running your crawl
- What to expect from archived Facebook seeds
- Troubleshooting
How to select and format your Facebook seeds
You can add Facebook pages, profiles, and/or groups to your collection in order to crawl, archive, and replay them as you would any other seed site, just so long as you remember to format and scope them according to a few simple rules.
Follow our standard guidance for adding seeds to your collection, and keep the following principles in mind:
- Be Specific! Limit seeds for specific users, groups, events, posts, etc. Do not crawl all of Facebook--don't forget to add an ending slash to your Facebook seed URL.
- Use the HTTPS version of the URL. Since Facebook serves its content exclusively from HTTPS, you can avoid potential crawl problems related to redirects by using "https://" instead of "http://".
- Use the Standard seed type. We advise strongly against using the Standard Plus seed type when crawling Facebook.
- Crawl for at least one day. Anything less than a one day long crawl will unlikely collect the data necessary to replay a Facebook page in Wayback.
- Check a seed's availability on the live web. Archive-It crawlers cannot access content from a Facebook page that requires a user to be logged in. It's possible to add user credentials to your Facebook seeds, however we advise against this. User credentials added to Facebooks seeds have sometimes been flagged by Facebook's bot tracker, which may result in that user account being locked.
- Use helper seeds. To optimize in-page navigation between subpages of an archived Facebook seed, add each subpage of the Facebook page you are crawling as its own private helper seed (Standard seed type) and crawl all seeds together. Setting the helper seeds to private ensures that the homepage of your Facebook seed, e.g. https://www.facebook.com/internetarchive/, remains the primary point of entry for accessing that content on your public landing page.Each helper seed will also have the default scoping rules added.
E.g. for the public seed https://www.facebook.com/internetarchive/, add https://www.facebook.com/internetarchive/photos/ and https://www.facebook.com/internetarchive/videos/ and set them to private
Note: Some Facebook subpages may look like this on the live web: https://www.facebook.com/pg/internetnetarchive/photos/?ref=page_internal. For the best possible capture, remove the "pg" in the middle of the URL and the ending string "?ref-page_internal" when adding these subpages as seeds.
Scoping Facebook seeds
Default scoping for Facebook seeds
New Facebook seeds added to collections will have the following default scoping rules applied automatically at the seed level; older Facebook seeds can be updated by adding the below scoping rules manually or following these instructions.
To learn more, visit Sites with automated scoping rules.
-
Apply seed-level data limit
Facebook data can range wildly, from 1 to 20 GB depending on the type of page and its content. Start by applying a seed-level data limit of 3 GB to each Facebook seed. If you do not get a complete capture or feel more data than necessary is being captured, try incrementally changing the seed-level data limit and run a new test crawl at each stage to determine the ideal limit for your seed.
2. Ignore robots.txt
Ignore robots.txt for each Facebook seed at the seed level.
OR Add collection-level scoping rules to ignore robots exclusions on the following hosts, exactly as they appear here:
- www.facebook.com - in order to archive Facebook-hosted content
- fbcdn.net - in order to archive important page styling elements
- akamaihd.net - in order to archive important page styling elements
3. Expand scope to capture scroll
To archive content from Facebook's dynamically scrolling pages, expand the scope of your crawl at the seed level to include URLs that match the following SURT, exactly as it appears here: http://(net,fbcdn,
Note that scroll on Facebook Groups' seeds (i.e. https://www.facebook.com/groups/) will be limited.
4. Exclude segmented video files
Facebook frequently serves videos in segmented files and the crawler will capture these segments in addition to files that contain the entire video. To exclude segmented video files, for all Facebook seeds add a seed-level rule to Block the URL if it contains the text: bytestart=
5. Exclude non-English interface
Limit the scope of your crawls to only archive the Facebook interface in English (this will not affect posts written in other languages) by adding a rule to block URLs that match the following regular expression: ^https?://..-..\.facebook\.com.*
If adding this rule to the Collection Scope tab, enter facebook.com in the host field.
6. Exclude personal user profiles
Prevent the capture of individual Facebook users' personal profiles from archiving by limiting your crawl to block all URLs that match the following regular expression: ^https?://www\.facebook\.com/(profile\.php|people/).*$
If adding this rule to the Collection Scope tab, enter facebook.com in the host field.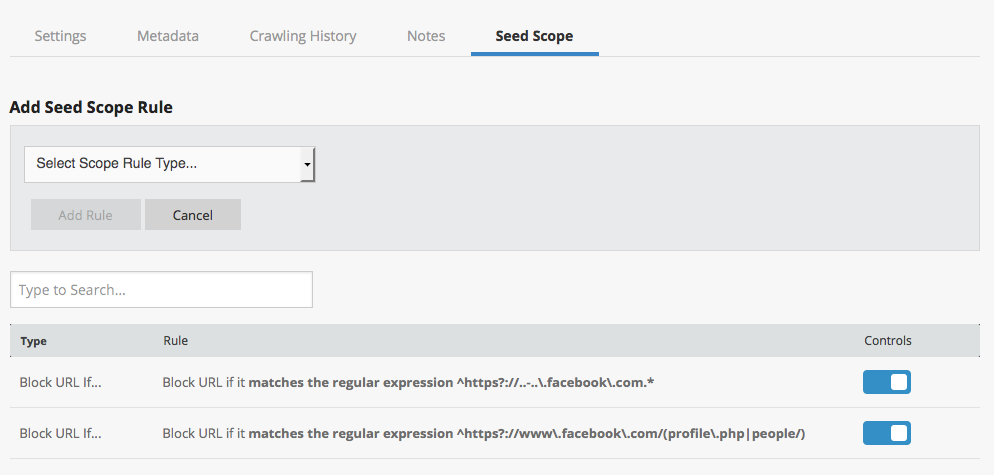
Embedded Facebook feeds
Scoping rules for embedded feeds are not applied automatically. To capture a Facebook feed embedded on a web page, add the above default scoping rules manually.
Running your crawl
Once you have finished adding your seeds and the recommended scoping rules (if necessary), we highly recommend that you run your crawl using Brozzler crawling technology.
We recommend running a test crawl after adding any new seeds or rules. Run your crawl for at least one day. Anything less than a one-day crawl is unlikely to collect the data necessary to display a Facebook page in Wayback.
What to expect from archived Facebook seeds
You can expect the following for recent Facebook crawls:
- Multiple distinct capture dates may appear on the Wayback calendar page for the time period of your crawl.
- Facebook intermittently blocks crawls of organizational and Groups pages. When not blocked, recent Wayback pages resolve to a blank logo page. For captures from unblocked crawls prior to mid-April 2025, Wayback replay is often limited to the top post. Limited additional content may be accessible in your crawl's File Types and Hosts reports.
- Individual posts - including photos and videos - can sometimes be collected and replayed successfully.
- You may need to wait several seconds and dismiss login prompts while the page loads in Wayback.
- Feed posts, comments, and likes will not expand when clicked.
- If collected, media can be replayed through the Wayback banner. You may be able to access addtional media content from within your crawl's File Types report.
Troubleshooting
- If you have a 3 GB data limit in place, and do not get a complete capture with all the default scoping rules applied, incrementally increase the seed-level data limit by 2 GB and run a new test crawl at each stage to determine the ideal limit for your seed. If pages undergo significan changes, recurring crawls may need one crawl with a higher data amount to capture the new content, before returning to a lower data amount.
- It is possible to use the Wayback QA tool on saved test crawls and production crawls to capture missing content. It is best to use this tool to run patch crawls as soon after a crawl ends as possible, because some URLs will be time sensitive, due to how Facebook serves up its content.
Comments
0 comments
Please sign in to leave a comment.