
Overview
YouTube is an online video sharing service and social media platform where users can watch, like, comment, and upload their own videos. You can add YouTube videos or channels to your collection in order to crawl, archive, and replay them as you would any other seed site, just so long as you remember to format and scope them according to a few simple rules. This guide provides an overview of how to properly format, scope, and crawl YouTube seeds.
Known issues
YouTube may block our crawlers making it difficult to consistently archive content hosted on their platform. Currently, YouTube has the following issues:
- ⚠️ We are aware of intermittent issues collecting YouTube videos. If successfully collected, you can replay videos through the Wayback banner. If not collected, try running a new test crawl.
- ⚠️ For channels and playlists, video watch pages may need to be opened in new browser tabs in order to replay. For pages with dynamic scrolling, the archived page might not display content below the fold and might repeat.
- ⚠️ Playlist crawls may collect videos outside the scope of the playlist's videos. We are working to resolve this issue.
You can find a full list of known issues for archiving various platforms on our Social media and other platforms status page.
On this page
- How to select and format your YouTube seeds
- Scoping YouTube seeds
- Running your crawl
- What to expect from archived YouTube seeds
How to select and format YouTube seeds
Watch pages
Individual videos on YouTube are hosted on a "watch" page with a URL in the following format:
https://www.youtube.com/watch?v=XXXXXXXXXX
Follow this formatting and always use the "One Page" seed type to avoid scoping in all of youtube.com.
- Format your seed like the above - do not put a trailing slash (/) at the end.
Channels and Users
YouTube channels are topic-specific groups of videos and related content. YouTube channel URLs can have multiple formats. For example, the University of Melbourne's channel can be accessed at https://www.youtube.com/user/unimelb/, and the Internet Archive's channel can be accessed at https://www.youtube.com/@internetarchive_/. This URL can serve as your seed URL.
- Format your seed like the above - put a trailing slash (/) at the end.
However, when you wish to archive a user's YouTube channel in its entirety, we further recommend adding an additional seed URL for its "Videos" tab, which is formatted as:
https://www.youtube.com/user/[user-name]/videos or https://www.youtube.com/@internetarchive_/videos
- Format your seed like the above - do not put a trailing slash (/) at the end.
This enables our crawler to access all videos uploaded to the user's account.
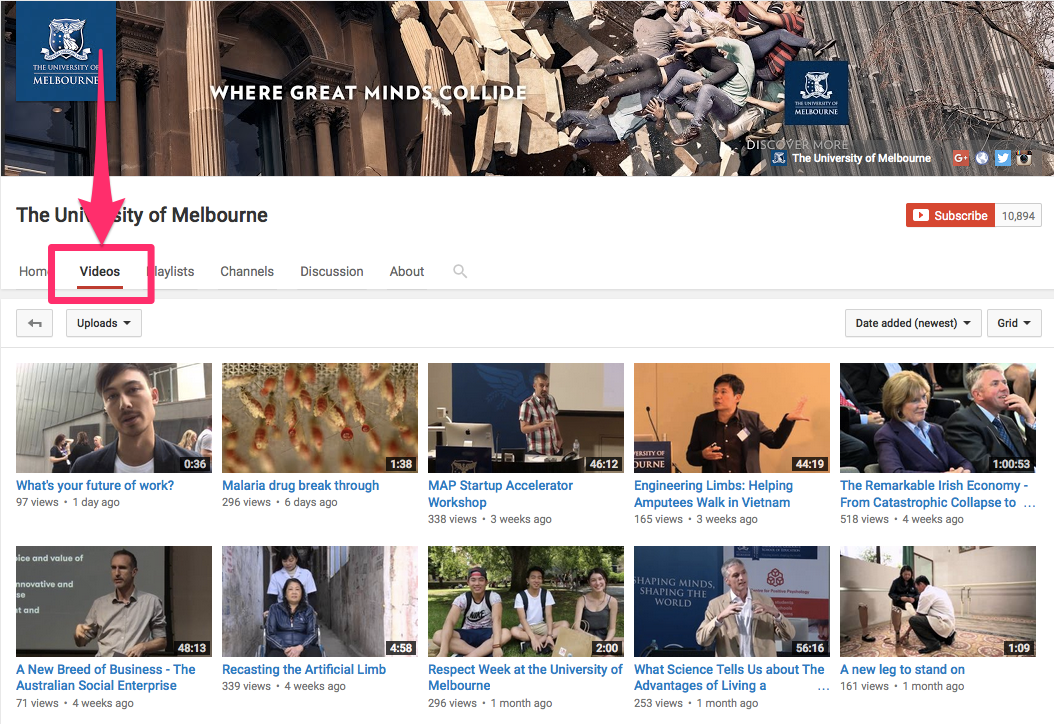
The Standard seed type is best for crawling the videos linked off of a channel page; however, a test crawl is strongly recommended when crawling a channel for the first time. Depending on the number of videos, these seeds can be very data heavy. Consider using the test crawl to determine how much data you should allot to these seeds then limit your crawl by adding a data limit at the seed level.
Playlists
Playlists are specific lists of videos curated by a user from among their account's and/or other videos on YouTube. The URL for each playlist can be added as seed, and is typically formatted as:
https://www.youtube.com/playlist?list=XXXXXXXXXXXXXXXXXX
To archive a playlist index and all of the video watch pages to which it links:
- Format your seed like the above - do not put a trailing slash (/) at the end.
- Use the "Standard" seed type.
- Crawl with Brozzler crawling technology.
Shorts
YouTube shorts are similar to video watch pages, but the videos are often under 1 minute. Their URL format is:
https://www.youtube.com/shorts/XXXXXXXXXX
e.g., https://www.youtube.com/shorts/d9lSqCOurrE
To archive individual Shorts videos:
- Format your seed like the above - do not put a trailing slash (/) at the end.
- Use a "One Page" seed type.
- Crawl with Brozzler crawling technology.
- Replay the video using the Wayback banner's media link.
- Shorts' placeholder images often display blank.
For Shorts collection pages, the URL format is often:
https://www.youtube.com/@[user]/shorts
e.g., https://www.youtube.com/@fifa/shorts
To archive Shorts collections:
- Format your seed like the above - do not put a trailing slash (/) at the end.
- Use the "Standard" seed type.
- Crawl with Brozzler crawling technology.
- To replay open individual Shorts videos' pages in new tabs (right-click the videos' thumbnail and select top option), then use the Wayback banner's media link to play back the video.
Search results
YouTube search pages such as https://www.youtube.com/results?search_query="william+shakespeare" are best crawled using the One Page Plus External Links (One Page +) seed type.
We strongly recommend a test crawl when crawling search pages. As with channels, to avoid crawling excessive additional videos you may need to limit your crawl by adding a data limit at the seed level.
Embedded videos
Videos that are embedded into other sites should archive successfully as long as the default scoping rules below have been applied to that site's crawl.
Scoping YouTube seeds
You can set up your crawls to archive videos from YouTube watch pages, channel pages, or embedded videos in other sites, by adding scope modifications at either the Collection or Seed level.
Default scoping rules for YouTube seeds
New YouTube seeds added to collections will have the following default scoping rules applied automatically at the seed level; older YouTube seeds can be updated by adding the below scoping rules manually or following these instructions.
To learn more, please visit Sites with automated scoping rules.
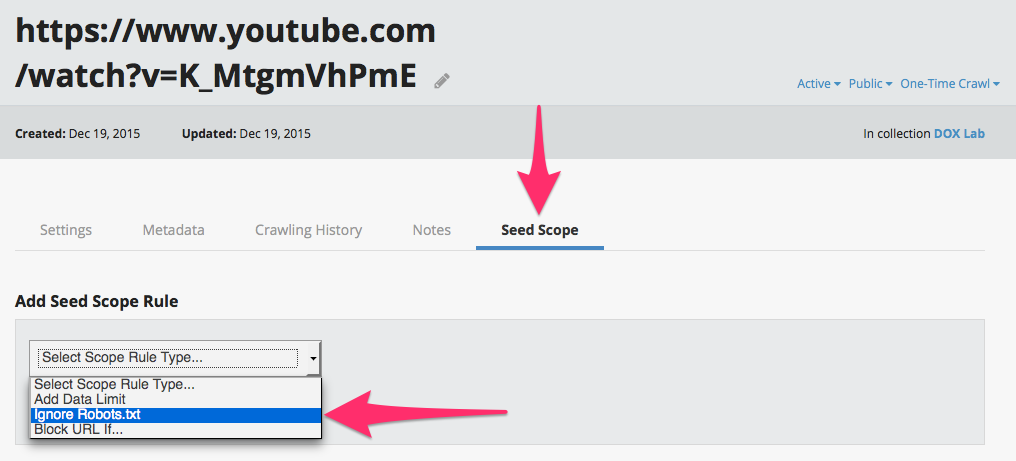
1. Robots.txt Blocks
YouTube blocks important page styling content and some video files with robots exclusions. To make sure that you capture the look and feel of a YouTube page and/or any video content, you will therefore need to add the rules listed below.
If you want to archive YouTube videos linked or hosted by any site in the course of your crawl, you must first modify your collection's crawl scope to ignore robots.txt files from the following hosts, exactly as they appear here:
- youtube.com [note: no www.] - This is one of the hosts that serves YouTube video files.
- googlevideo.com [note: no www.] - This is the primary host that serves YouTube video files.
- ytimg.com - This host serves stylesheet and JavaScript content necessary for playback.
- OR -
If you prefer to archive only those videos and video pages from the specific YouTube seed that you added to your collection: Ignore robots.txt for each seed.
2. Crawler traps
Sometimes, YouTube crawls run into crawler traps and archive invalid URLs with seemingly endless combinations of repeating directories. This is the most common crawler trap that affects the host www.youtube.com, as in this example:
https://www.youtube.com/channel/UCrHC0hXTvYewidE9Q5AM_8w/_/im/HTTP/www/www/HTTP/HTTP/www/HTTP/HTTP/www/www/channels
This issue can be addressed in the seed scope by adding the following rule to Exclude document if it matches the regular expression:
^.?(/.{2,}?/).?\1.$|^.?/(.{2,}?/)\2.*$
Optional scoping rules for YouTube seeds
Scoping Googlevideo.com
Host-level data limits apply individually to each subdomain of that host. Because googlevideo files are served from a large number of individual subdomains, adding one rule to limit the amount of Googlevideo content often isn't enough. For example, a 1 GB data limit on the host googlevideo.com could result in 1 GB from r5---sn-n4v7sn7s.googlevideo.com, 1 GB from r3---sn-n4v7sn7s.googlevideo.com, and so on.
The easiest way to limit the amount of googlevideo content is to identify the seeds from which googlevideos are being captured, and add seed-level data limits to them. The size of the data limit will vary depending on your seed, so be sure to run test crawls to make sure you're capturing what you need.
Running your crawl
Once you have finished selecting your seeds and adding recommended scoping rules, we recommend that you crawl your seeds using Brozzler crawling technology. Running a test crawl is highly recommended when crawling new YouTube seeds for the first time.
What to expect from archived YouTube videos
Archived YouTube content in Wayback currently replays most reliably in Chrome. If you do not see your videos replaying as expected, check the link in Chrome before submitting a support ticket.
If you collected YouTube using Standard crawling technology and are having trouble replaying it, consider running a new crawl using Brozzler.
If Wayback resolves to a "not archived" message and the URL is appended with “&themeRefresh=1”, turn off your computer or browser’s dark mode. A "&themeRefresh=1" parameter can be introduced by browser extensions and can cause continuous page refreshes that prevent the Wayback page from loading.
Individual watch pages: Archived videos might not replay within the page. The video can be replayed by selecting the play media button in the Wayback banner.
Channels, playlists, and search results: Individual watch pages may need to be opened in new browser tabs in order to replay. For pages with dynamic scrolling, the archived page might not display content below the fold and might repeat.
Embedded videos: Archived videos might not replay within the page. The video(s) can be replayed by selecting the play media button in the Wayback banner.
Comments
0 comments
Please sign in to leave a comment.