
Welcome to this Quickstart Guide on how to use your Archive-It account.
This article is intended for new users in the Archive-It Trial account. If you are interested in trying an Archive-It trial, please complete this form.
The below steps are the basis of a workflow to archive web-based content after you have logged into the Archive-It Trial account.
- Step 1: Access Collection
- Step 2: Add Seeds
- Step 3: Scoping
- Step 4: Run a crawl
- Step 5: Check the Crawl Report
- Step 6: Check your archived Wayback pages
- Further reading
Step 1: Access Collection
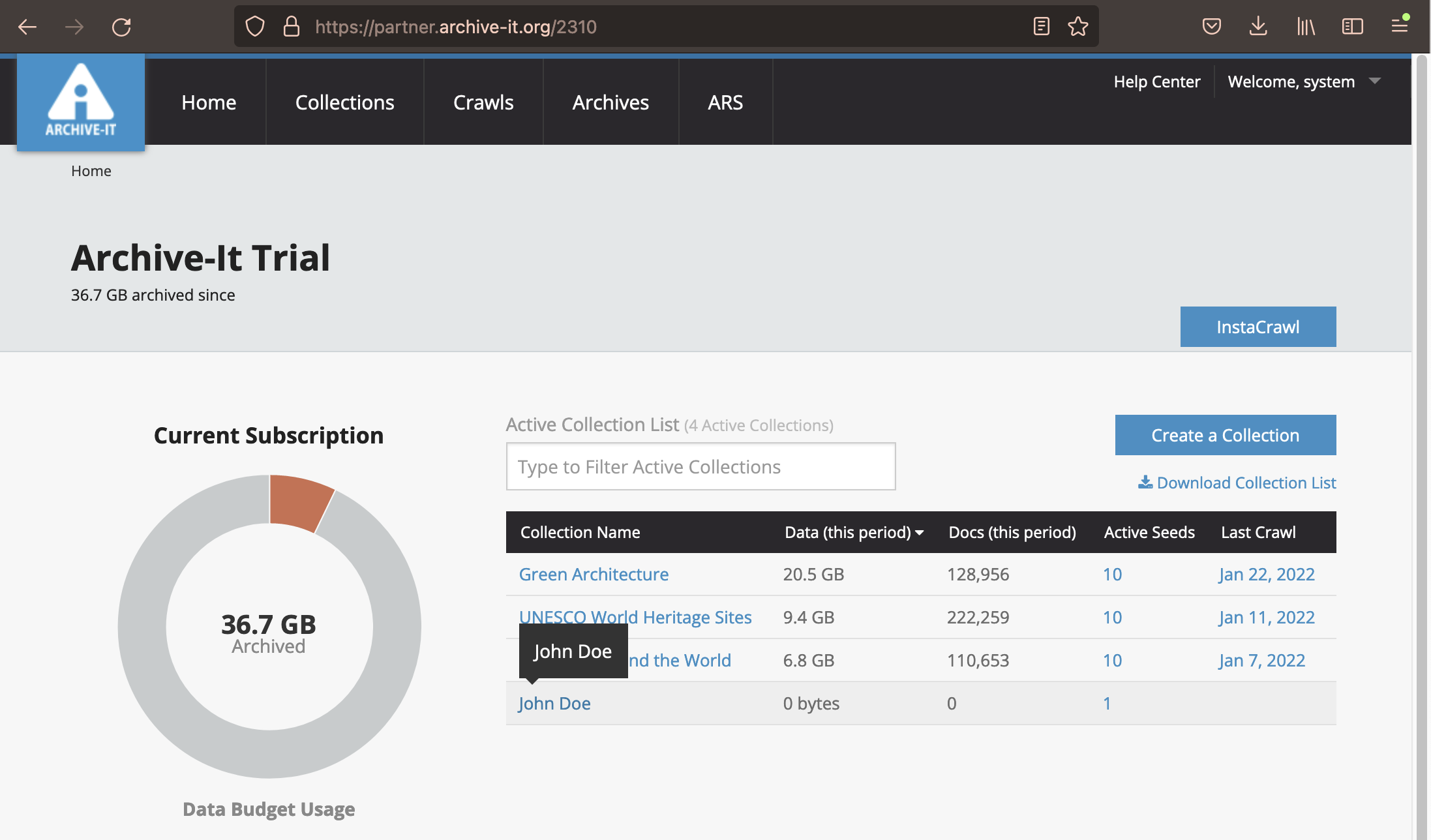
Anything archived in Archive-It is organized in Collections, so the first step is to access your Collection. In the center of the page you will see links to Collections. The first three Collections are built by Archive-It as examples of what you can do with your own collection. Below them, you can access your own collection by clicking the link with your name on it.
Step 2: Add Seeds
After you have accessed your Collection, the next step is to add Seeds. A seed is the starting point URL for the crawlers as well as the access point for any archived pages. Adding a trailing slash to the end of the URL will keep the crawl to a default scope, and prevent it from gathering too much data.
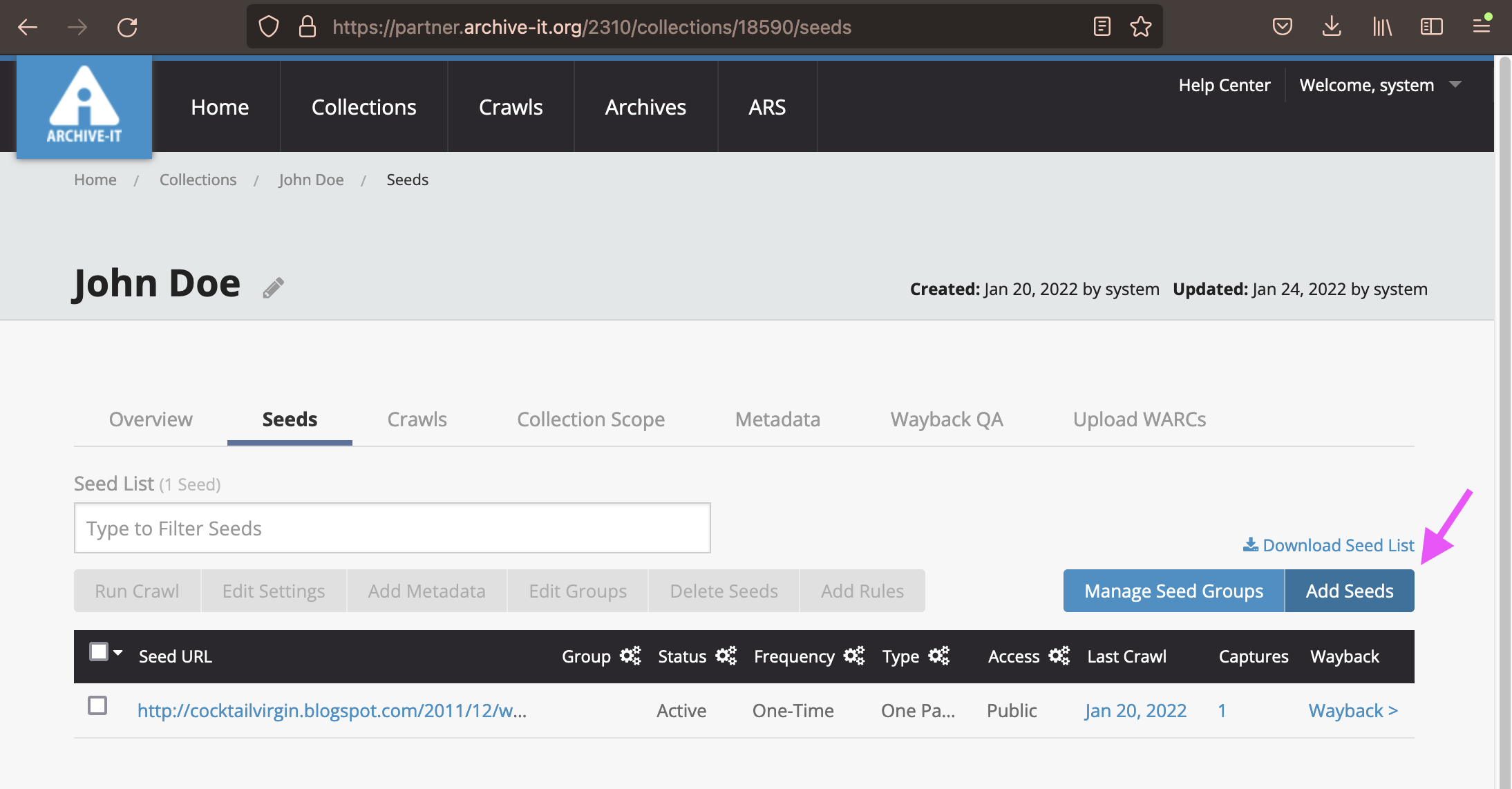
Click on the "Seeds" tab, then click the "Add Seeds" button.
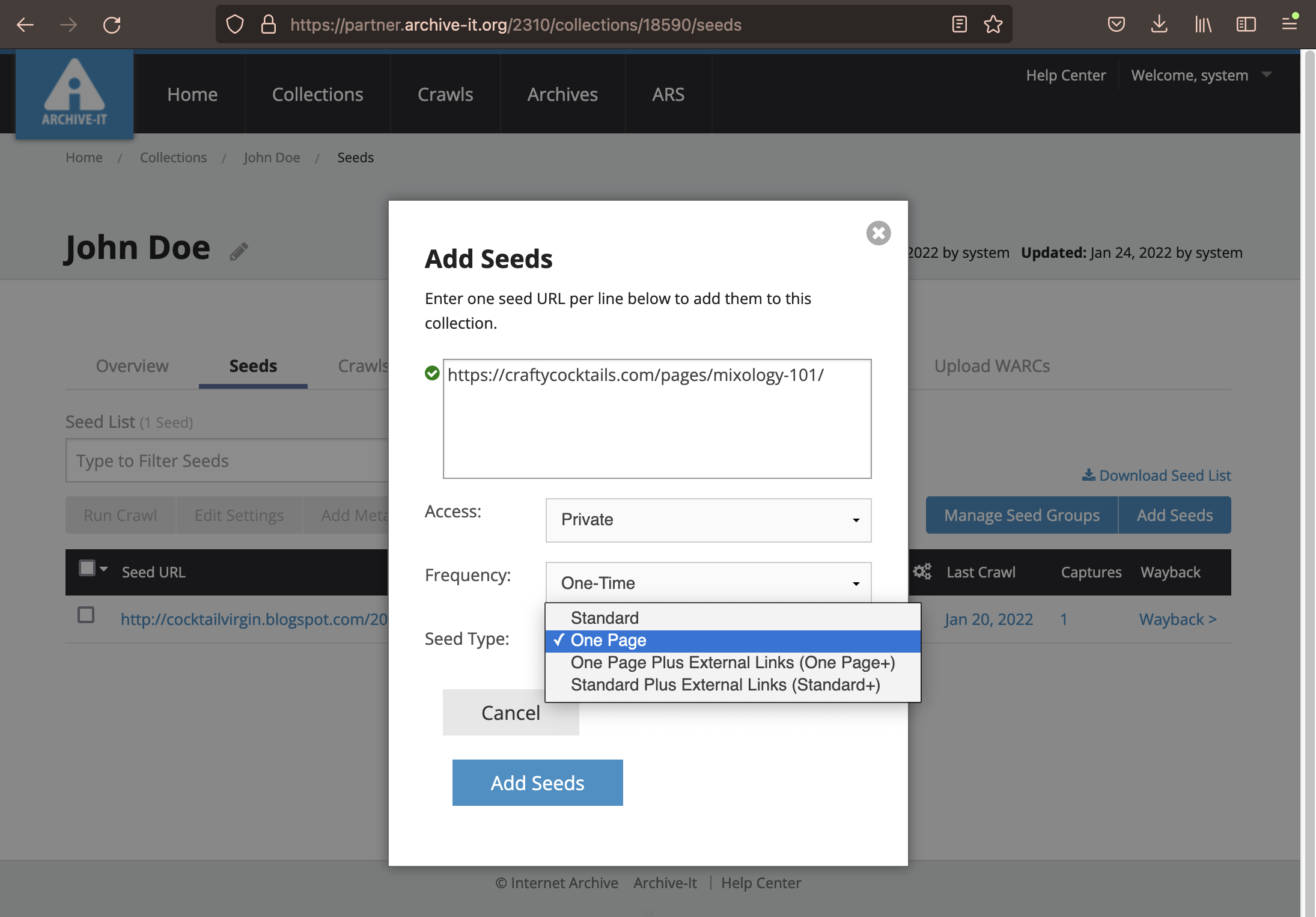
Clicking this button will trigger a popup, where you can enter your seeds into the middle box. Select an access level (public or private), a Seed Type, then click the "Add Seeds" button.
Step 3: Scoping
Every Seed and crawl has a default scope to prevent the crawl from capturing the entire web. You can adjust this scope; in fact some platforms require scoping adjustments to archive fully. In some cases, seeds have scoping rules automatically applied, but in other cases, you will have to add them. Please see this page for a list of platforms that need special rules, along with instructions for adding these rules: https://support.archive-it.org/hc/en-us/sections/201841373-Scoping-crawls-for-specific-types-of-sites. Not adjusting the scope can result in essential content not being captured.
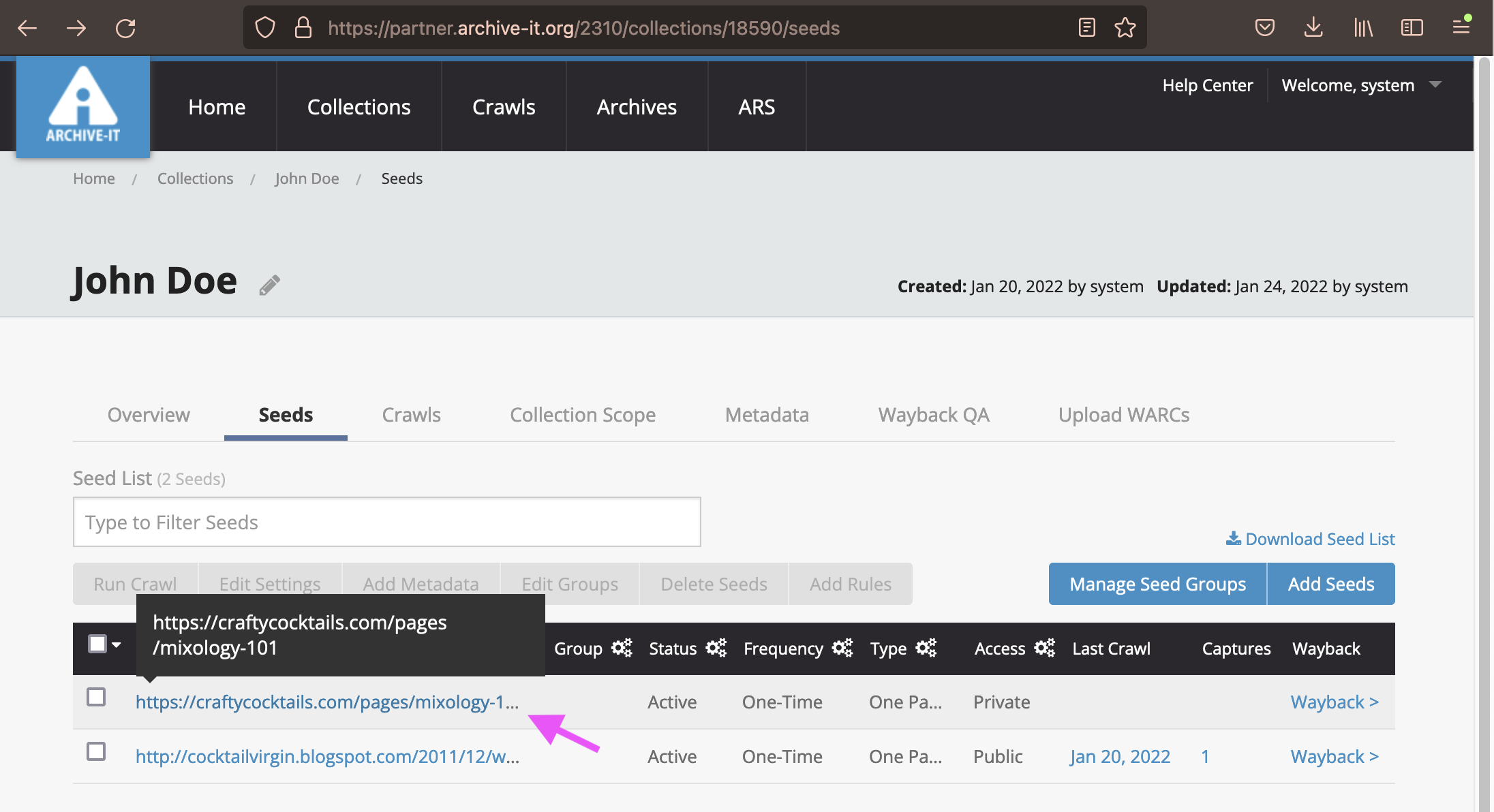
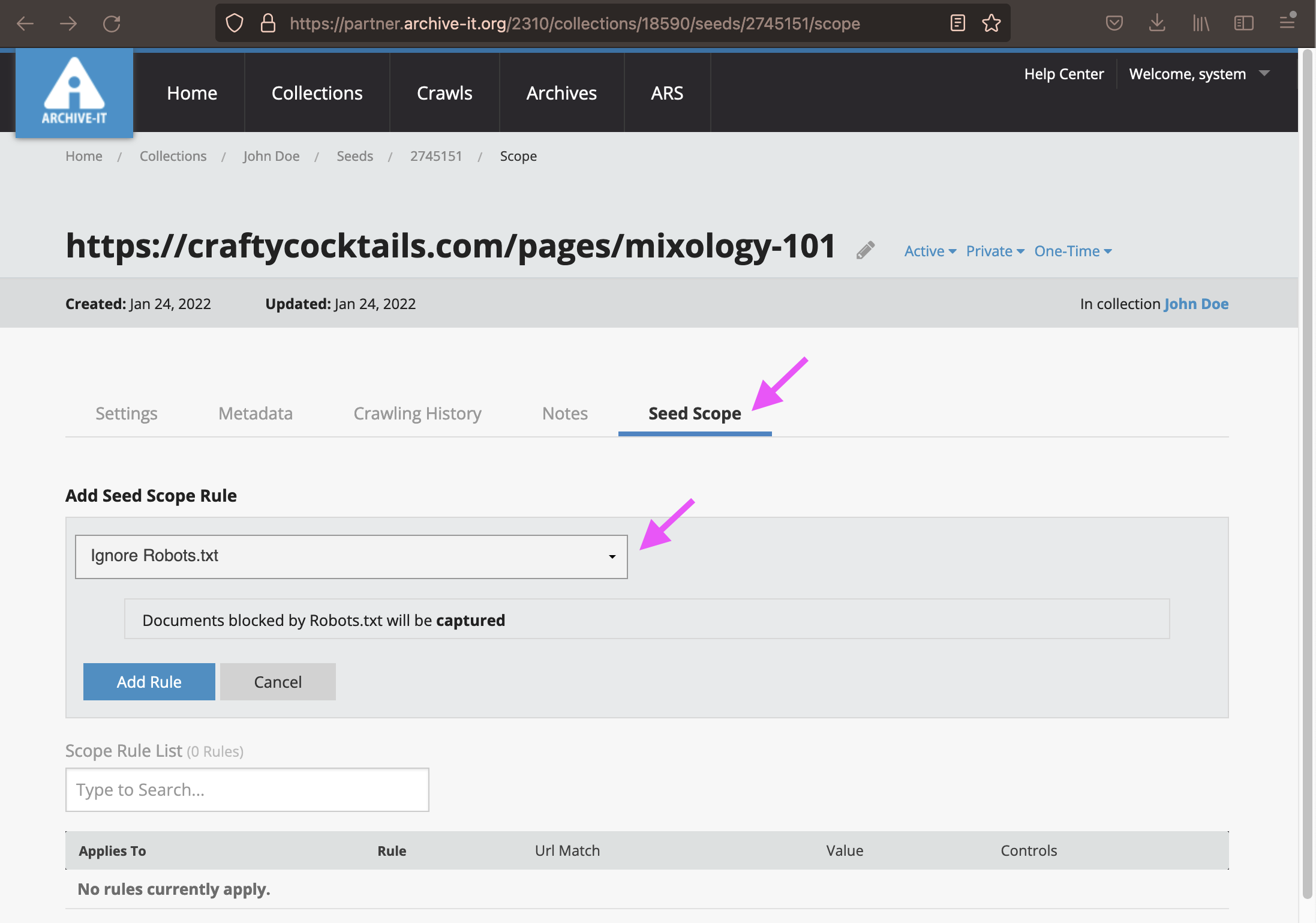
To add Seed Scoping rules, click directly on the Seed URL in the Seeds list.
Then choose the "Seed Scope" tab on the right. After that, use the drop down menu to choose the rule, and click "Add Rule."
Step 4: Run a crawl
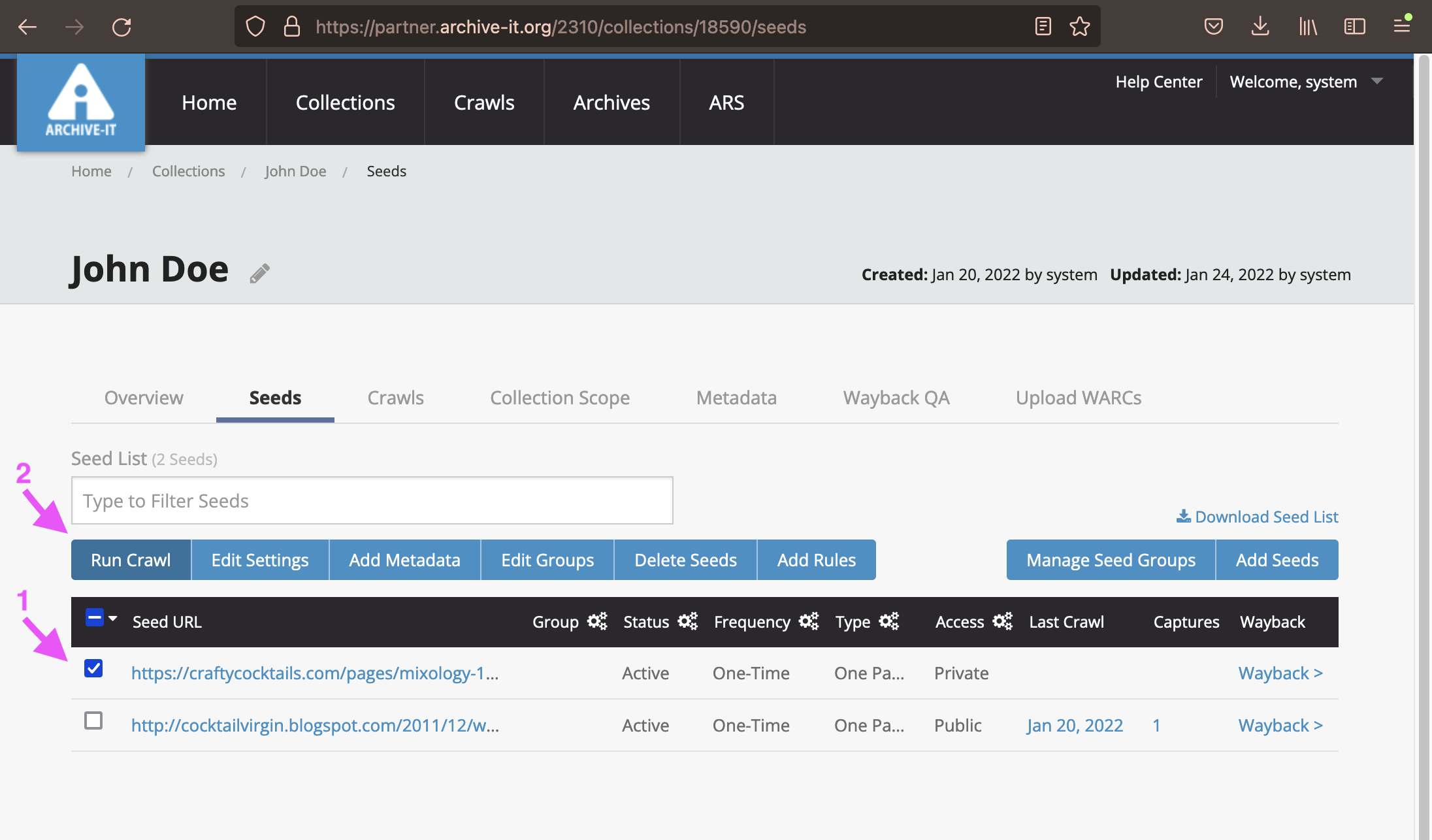
Once the collection is created and seeds are added and scoped, you're ready to run a crawl. Select one or multiple seeds, then click the "Run Crawl" button.
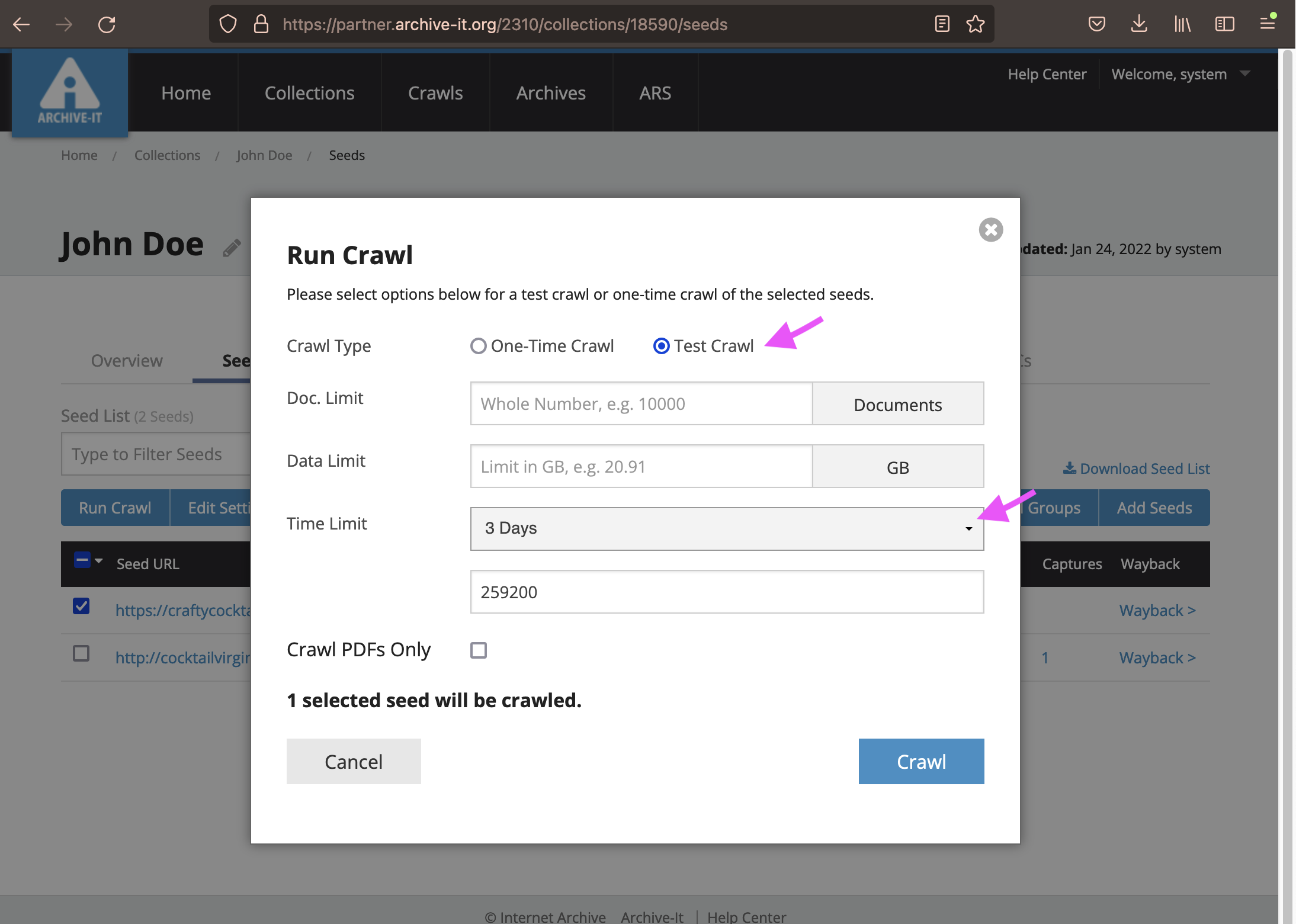
Clicking this button will generate a pop up box. Here you have several choices. Most important of these choices are the "Crawl Type" and "Time Limit".
- There are two types of crawls: "One-Time" and "Test". Test crawls are recommended for Trials. Test crawls hold the data temporarily for 60 days. One-Time crawls are permanent and can not be deleted.
- You can select a "Time Limit" between 10 minutes and 7 days. Generally speaking, most websites will take between 1-day and 5-day crawls to capture.
- You can also select a "Data Limit" up to 10 GB. Crawls have a default Data Limit of 10 GB in the Trial Account, unless otherwise specified.
Click the "Crawl" Button and check back in your collection when the Time Limit is up.
In general, Best Practices for first time crawlers are:
- Select 10 or fewer seeds at a time (if possible)
- Use the Standard seed type, unless you know you only want One-Page (avoid + seed types for now)
- Crawl Type - Test
- Time Limit - 5 days
- Crawling Technology - Brozzler
Step 5: Check the Crawl Report
After ending, each crawl generates a "Crawl Report" that includes details on what was and was not captured in that crawl, and why. Checking the Crawl Report is an essential part of Quality Assurance.
To access the crawl reports, click on the "Crawls" tab to access a list of "Crawl ID"s. Click directly on the "Crawl ID" number to open the Crawl Report.
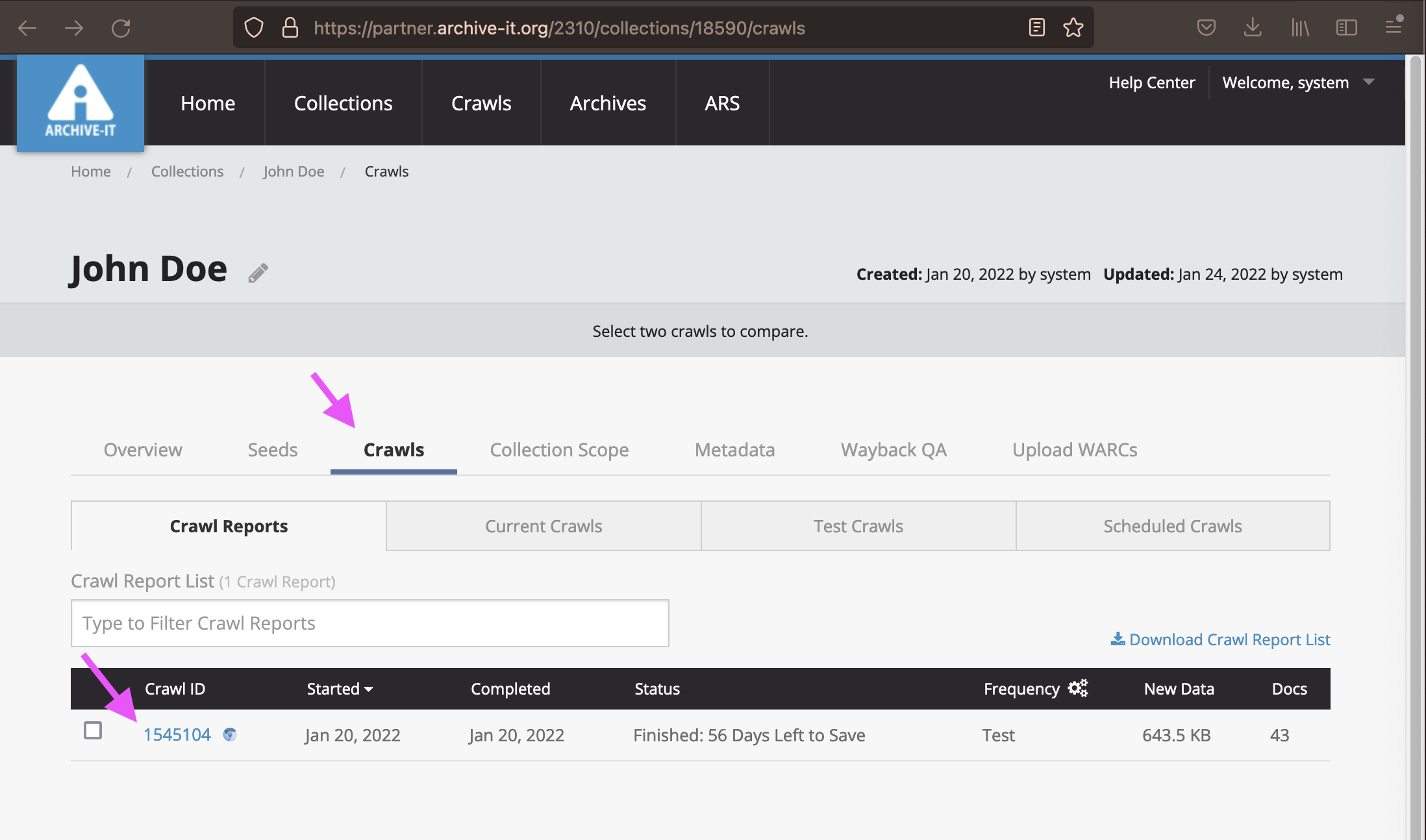
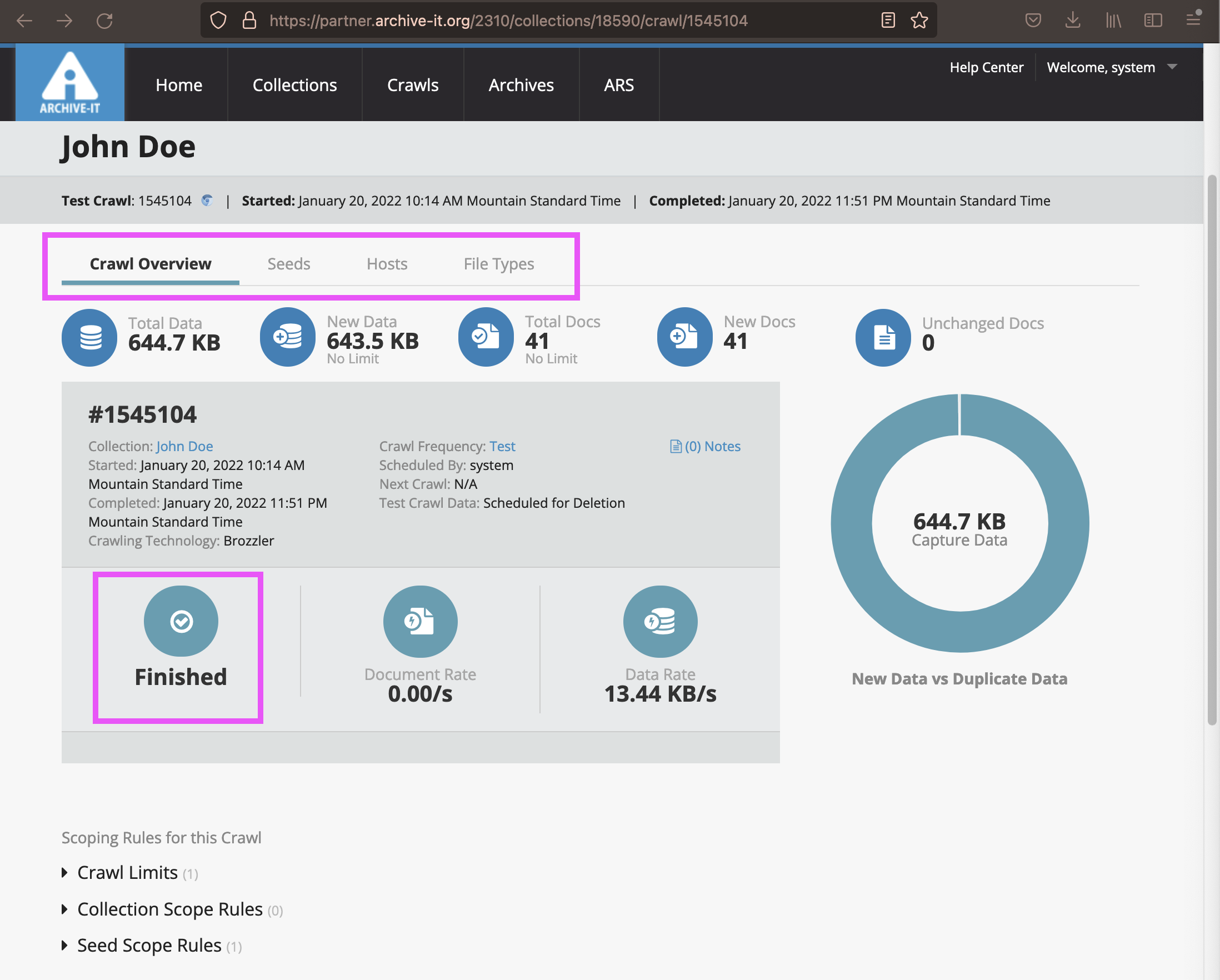
- You can use the "Crawl Overview" to see how much data was collected, and the crawl status, among other things.
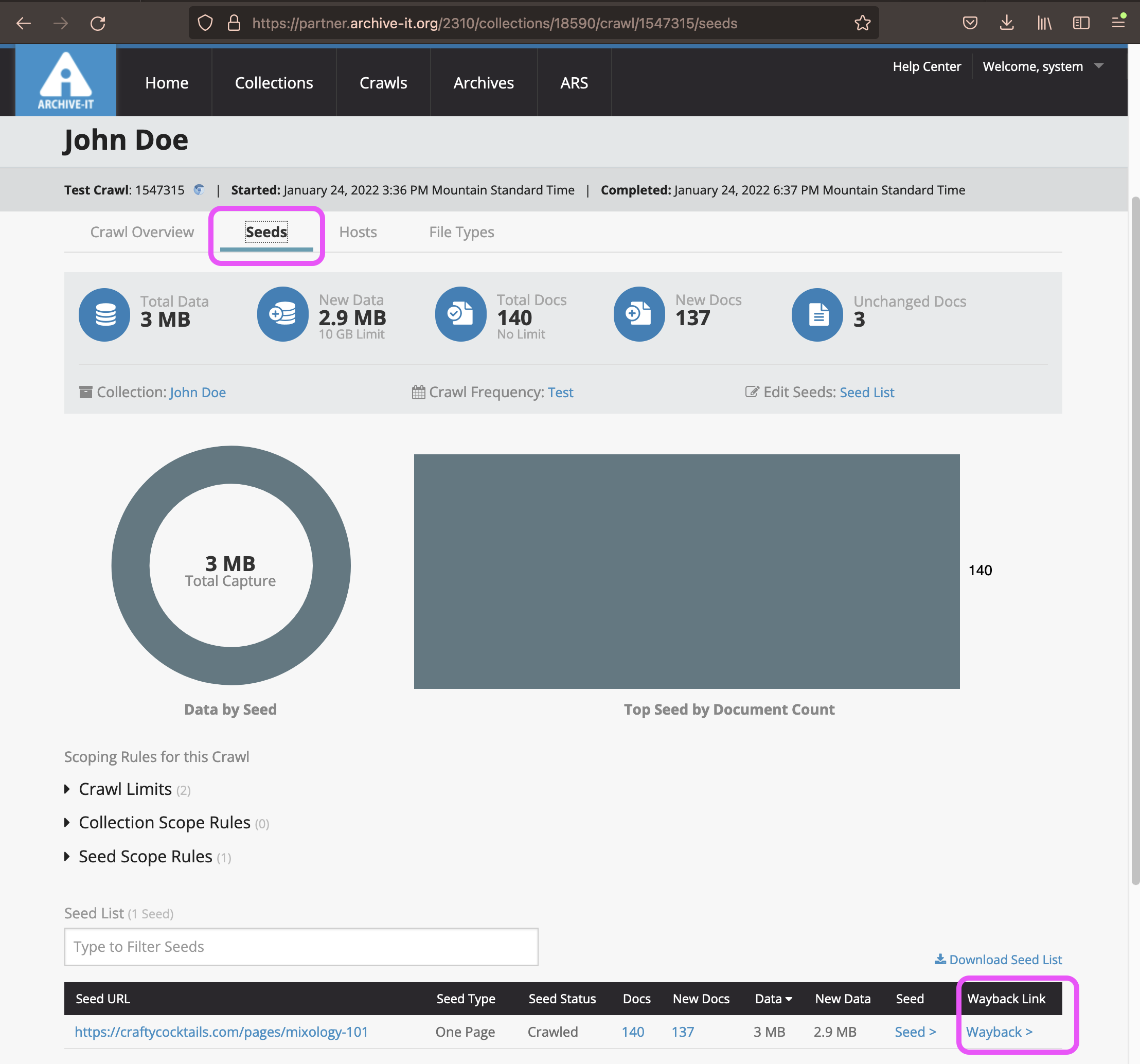
- The "Seeds" tab is where you can access your archived pages via the Wayback links. For test crawls, this is the only place to access your archived pages.
- The "Hosts" tab contains a list of all the places (known on hosts) from which content was collected. You can use this tab to see in granular detail what was, and was not, captured.
- The "File Types" tab contains the same information as the Hosts report, but broken up by the type of file.
Step 6: Check your archived Wayback pages
Browse your archived Wayback pages to ensure that everything was captured 24 hours after the crawl completes. To open the archived Wayback pages, in your crawl report's "Seeds" tab scroll down to find the "Wayback Links" in the bottom right.
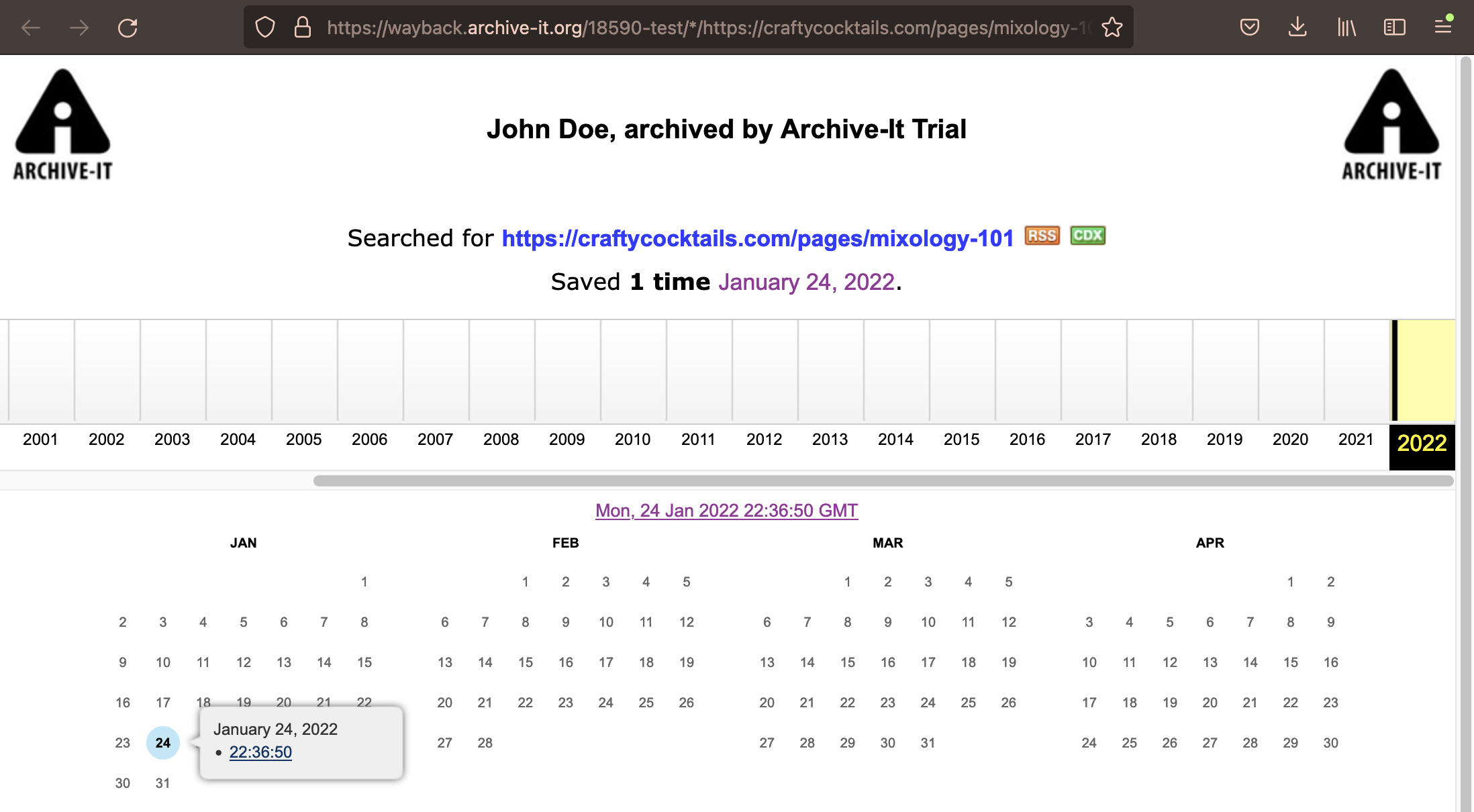
This "Wayback Link" opens the Calendar page for the archived pages' captures. Hover over a date, then click the time to open the archived page.
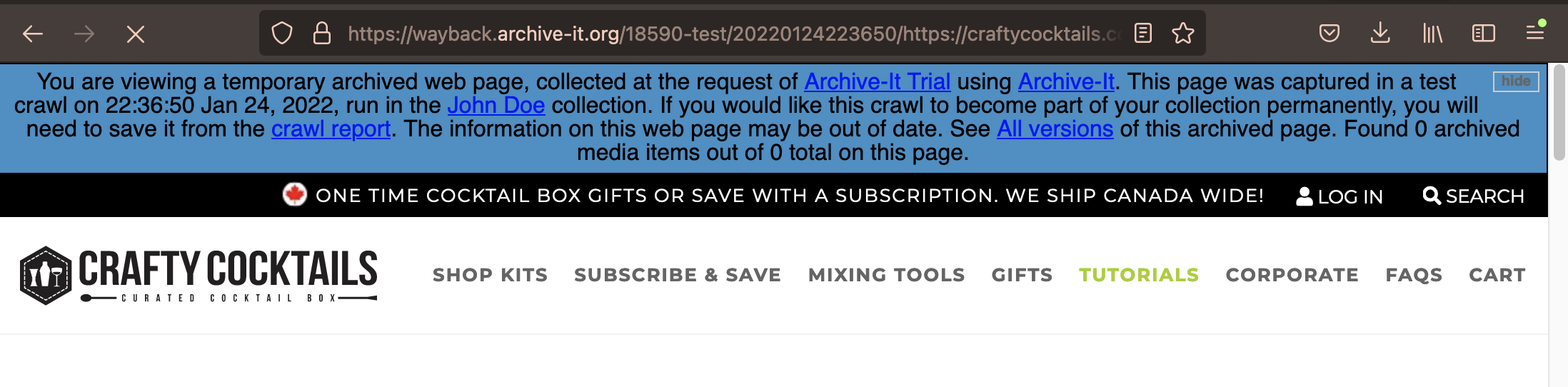
Your archived page should have a blue banner across the top with information about when it was archived. This is how you'll know it's an archived page and not the live website. You can copy and paste the Wayback URL from the browser's address bar to share it with your team and stakeholders.
See something unexpected? Please check our System Status page for any platform issues, or search in the Help Center.
Further reading
To get the most out of your Archive-It account, we recommend exploring our Help Center and Blog, including our Guide for New Users, Workshop series, and Video Curriculum.
Comments
0 comments
Please sign in to leave a comment.