
![]()
Archive- It 5.0 is our next generation (and completely redesigned) web application for archiving the web. This new version of the web application is the result of direct feedback from our partner community and our 10 years of experience providing the leading web archiving service for collecting and accessing cultural heritage on the web.
Features and enhancements:
User interface
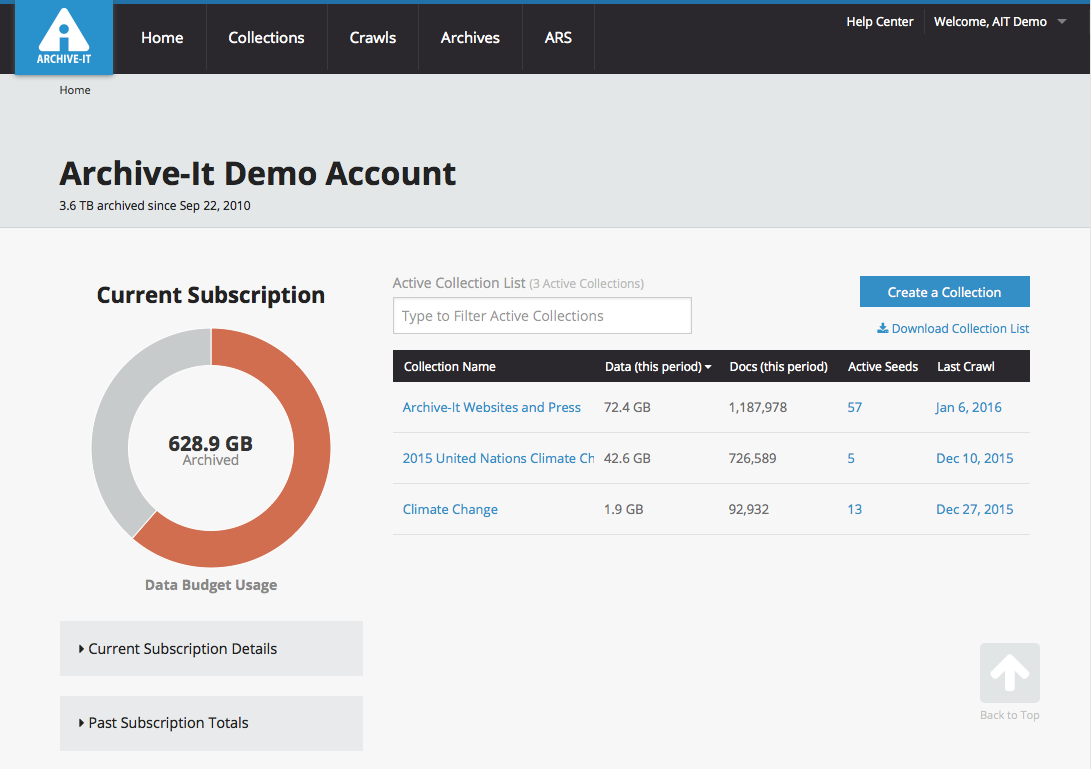
The centerpiece of our 5.0 software release is the totally redesigned user interface of our web application, the first total redesign since our launch in 2006. This sleeker, modernized, graphical UI will make the experience of archiving web content easier and more efficient.
Account management
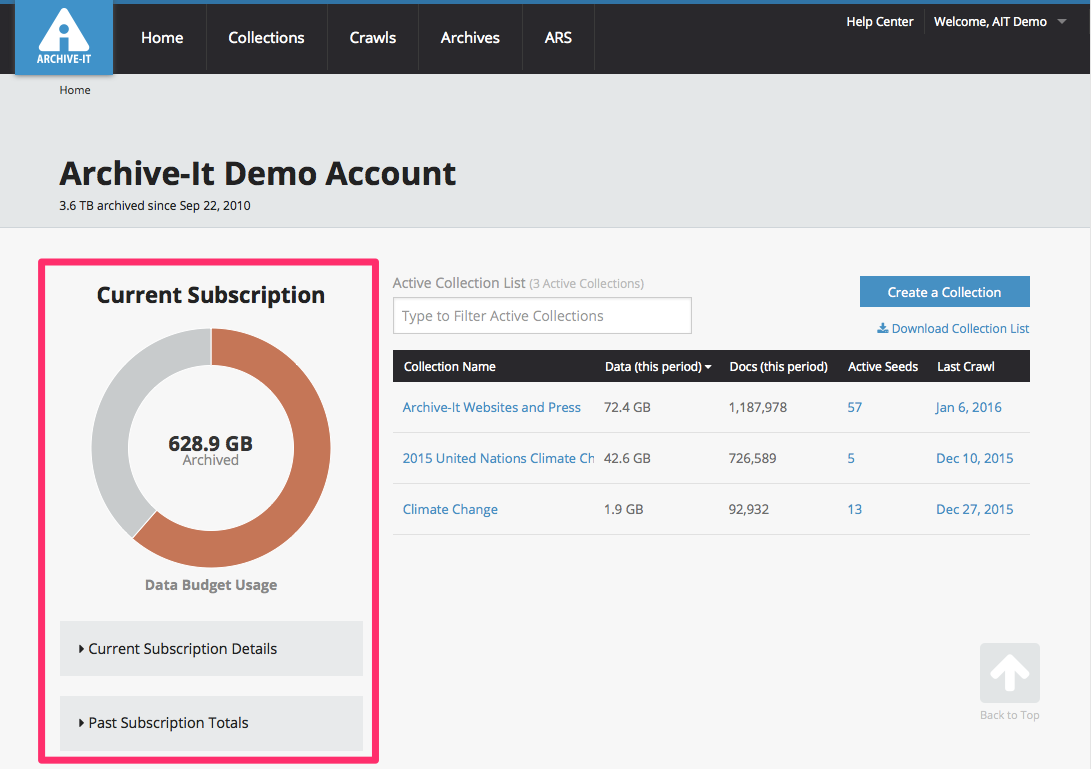
To make managing annual subscription details simpler and easier, we are phasing out annual document budgets in favor of a single data budget. Statistics on year-to-date and total documents and data archived can still be found on the account homepage. However, the figures and graphic provided for archived data provide an simple overview of current subscription data usage.
Collections
Rich seed management information
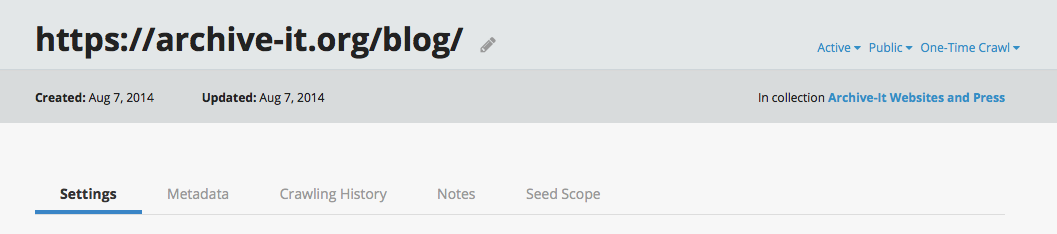
Partners can now manage seeds with detailed new information, including seed-specific crawl histories and post crawl reports. This will help quickly access and assess seeds' settings, metadata, and scope modifications.
New and enhanced seed types
Highlights:
- Assign/edit seed "type" to archive more or less material by default
- Archive material that had previously been "one hop" outside of default scope setting
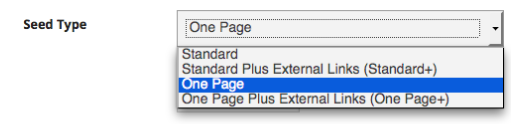
Partners have long had the ability to apply specific scoping rules to their seeds automatically upon their creation by assigning them a "type." In the past, these have included a "Default" type for most websites, a "One Page Only" type to archive single web pages without following their out-bound links, and an "RSS/News Feed" type to crawl and archive only the newest links as they are added to a regularly updated page or feed. With Archive-It 5.0, partners can use these same options (just with slightly different names) and some new ones:
- Standard: Crawl and archive any seed with the default scope settings.
- Standard Plus External Links (Standard+): Crawl and archive with default settings, but also include the first linked pages outside of the normal crawl scope. This type has also been known asOne Hop Off.
- One Page: Crawl and archive a single web page and its components without archiving outside pages linked.
- One Page Plus External Links (One Page+): Craw and archive a single web page, its components, and the first linked pages that would otherwise be considered out of scope.
For complete guidance on these new and enhanced types, and when/how to apply them see: How to assign and edit a "seed type"
Seed-level scoping rules
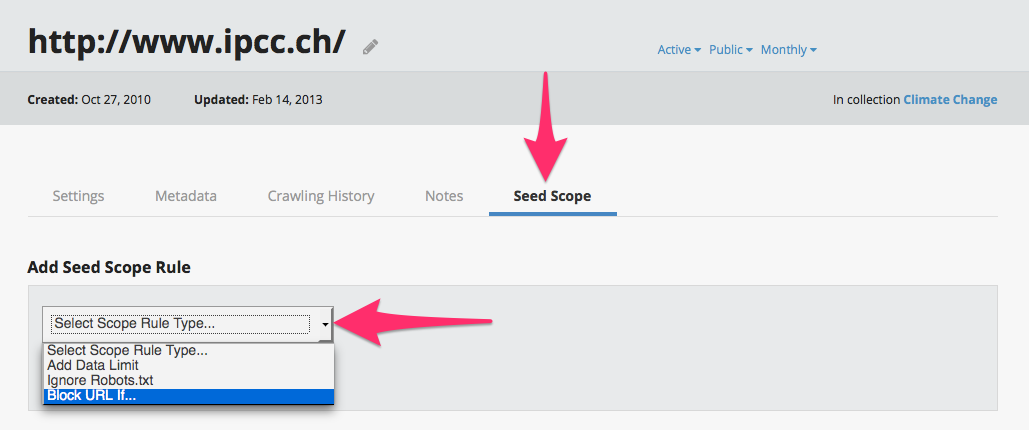
Crawls can now be designed to apply scoping rules at the seed level, meaning that partners can expand or limit the data archived from specific hosts depending upon the seed. Previously, the feature had only been enabled at the collection level, to simultaneously apply to all crawls and seeds in a given collection. This will help specifically define the precise material that partners do/don't want to collect for their archives.
Scope-It superseded by new and enhanced tools
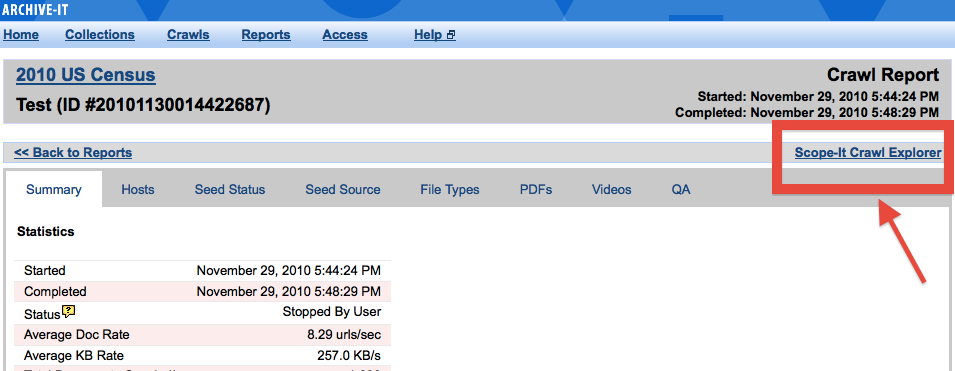
In the past, some partners used the "Scope-It Crawl Explorer" feature in order to identify hosts that require custom scope modifications, such as expansions, robots.txt evasions, and data/document limits. Archive-It 5.0 enables making all of these same modifications and more at the collection or the the seed level, and directly from Hosts report. Scope-It will continue to be available in Archive-It 4.9 until all partners are transitioned to the new web application; it will not be available in Archive-It 5.0
Crawls
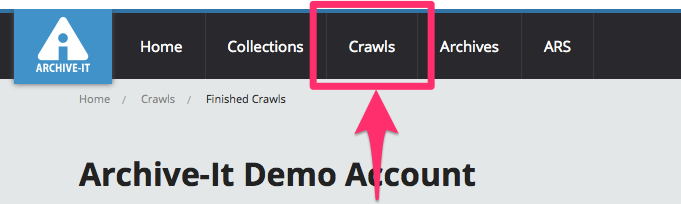
In Archive-It 5.0, the "Crawls" and "Reports" sections are consolidated into a new "Crawls" section from which partners can manage and analyze all crawls in their account, including current and completed crawls, test crawls, and scheduled crawls. Keeping all of these resources in proximity helps efficiently manage current, scheduled, and completed crawls together.
View and save test crawls
Highlights:
- View the results of test crawls in Wayback 24 hours after they complete
- Review reports for test crawls, including dynamically updating reports for those actively in progress
- Save the results of test crawls for preservation or delete them in order to better manage your subscription budget
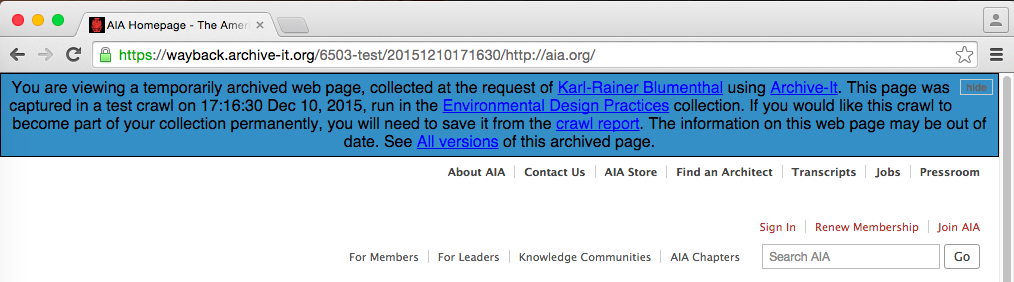
Test crawls are much more powerful in 5.0. Like normal production crawls, test crawls can now be viewed in Wayback 24 hours after a crawl completes. If desired, the crawl and its data can be saved and included in a partner's collection, or else deleted and re-crawled. If a test crawl is not saved, the data is automatically deleted after 60 days and will not count against an account budget. Reports for deleted test crawls will remain available. Note: Test crawls that ran before the June 2015 release will carry the Status "Finished: Deleted (Expired)." This new functionality will help partners evaluate how seeds crawl and allow for review of captures and scoping before adding the results of a crawl to their collections and counting towards a data budget.
Monitor current crawls
Highlights:
- View crawl reports as they update in real time, including detailed seed, host, and file type information
- Get real time information on the individual URLs and the amounts of new and total data crawled as a crawl progresses

Crawl reports are now available for currently running crawls in real time, including up-to-the-minute and detailed information about documents and data archived. All current crawls furthermore include a dynamically updated window that allows partners to track individual URLs as they are crawled. All other crawl reports (Seeds, Hosts, File Types) can likewise be viewed while a crawl is running. This will help partners evaluate the scope and effectiveness of crawls well before they complete – an especially helpful new ability for multiple-day crawls. For more information on this new feature, see our full guidance on monitoring current crawls.
Resume stopped crawls

Partners can now resume a finished crawl within seven (7) days of it ending, and with expanded limits in place. This new feature allows a crawl that has stopped due to a time, data, or document limit, or that a user stopped manually, to continue for a specified amount of additional time, capturing URLs that may otherwise be queued. This tool will be helpful when deciding that a collection would benefit from more crawling without necessarily scheduling a new and completely separate crawl to run.
Annotate, filter, and compare post crawl reports
Archive-It 5.0 now has discoverable reports! In our web app's new "Crawls" section, you can now quickly filter and search through all of your post crawl reports. Search by any text that is available in the reports, including a new field for custom notes. Notes will allow partners to annotate and comment upon crawls.
New information included in post crawl reports
All crawl reports now include:
- The names of account users who started and, when applicable, ended a crawl, so partners can better track and manage your team's workflow
- Any scoping rules that were in effect when the crawl ran, giving partners the opportunity to analyze the effects of scope modifications
- And enriched File Types report, from which users can now browse, access, and apply metadata to all files archived by format
- The ability to toggle views between all or just new data crawled--an easy way to understand and analyze the effects of de-duplication on a crawl
Actionable host reports
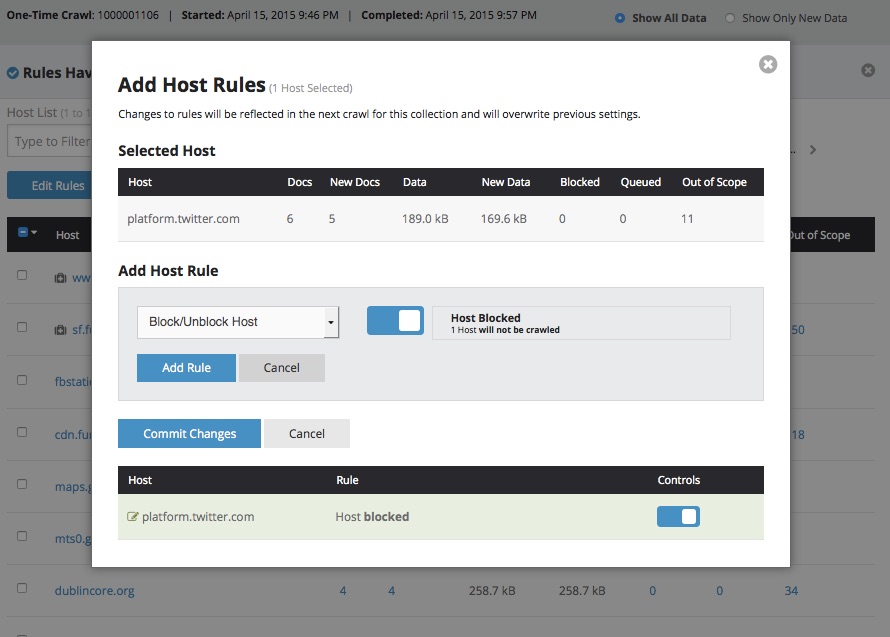
Host reports are now more powerful and feature-rich! When reviewing the results of crawls, users can now launch patch crawls of missing documents, ignore robots exclusions on additional hosts, and limit the data archived from other hosts directly from a report. This will help to make workflows more efficient by bringing together actions previously distributed across different sections of the web application.
No more QA Reports at the crawl level
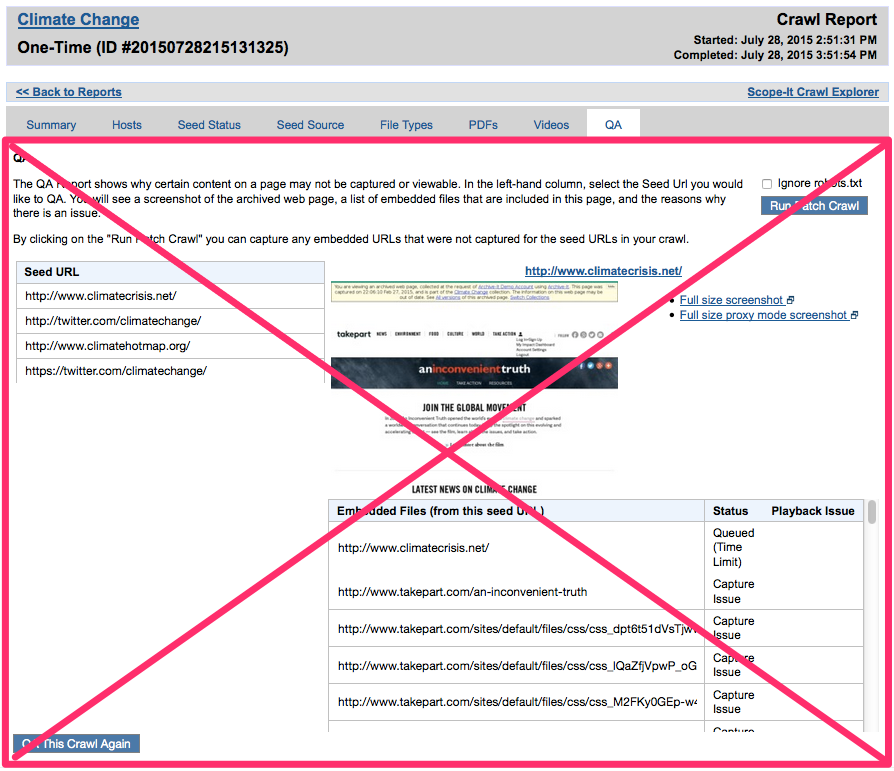
In the past, partners had to run a "QA Report" in order to find out which, if any, hosts from a crawl were blocked by robots exclusions or were otherwise missing URLs. Thanks to the new Actionable Host Reports (see above), partners can now identify, and take action on, missing content right from a crawl's Hosts Report.
Seed-specific host reports
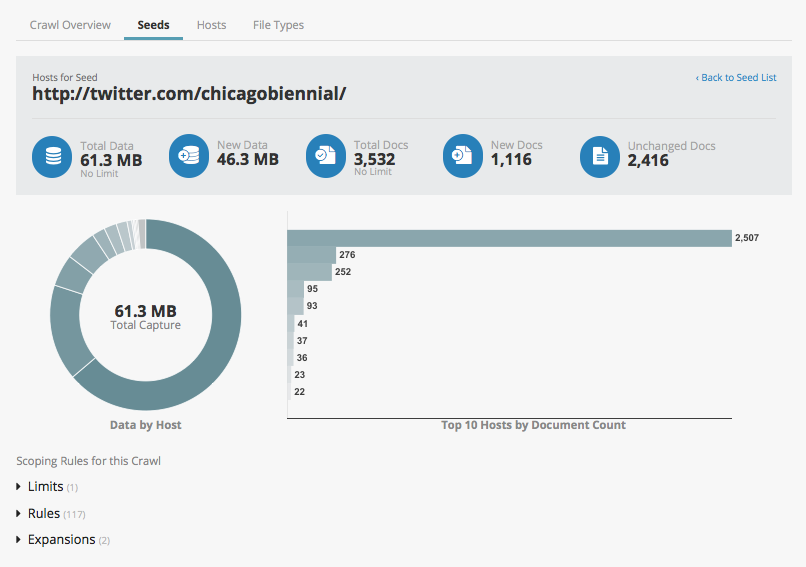
Seeds reports now include their own detailed information on the individual hosts crawled. In addition the traditional Hosts report, which covers all hosts found during a crawl, partners can now drill down into individual seeds to analyze their specific hosts and respective crawl information. This will help identify which seeds lead the crawler to which precise hosts as will assist in planning crawling scheduling, budget management, and scope modifications.
Launch Wayback from your reports
View archived URLs in Wayback directly from crawl reports! When browsing through a Seeds report, partners can now click the "View" link to launch the site in Wayback, skipping the need to first navigate to the former "Access" area of the web application. This is an especially useful tool to use when evaluating the results of test crawls.
Access
Metadata
Archive-It 5.0 has improved features for managing metadata, including detailed new error reports and confirmations of changes/additions for bulk metadata uploads. Additionally, partners can now export metadata, even in the form of a simple spreadsheet.
Proxy Mode Toggle
Viewing archived sites in Proxy Mode is a whole lot easier now, thanks to the new Proxy Mode Toggle Button for Firefox. Rather than worry about complicated proxy server settings for each browser, adding this feature to the Firefox browser allows users to switch between Wayback and Proxy modes with one click.
Google Analytics
Partners can now track and analyze access to their account on https://archive-it.org/ with the new Google Analytics integration. Analysis and management of statistics is handled through logging into Google Analytics directly. This is a quick and easy way for partners to get quantitative metrics on, and insight into, user traffic to their Archive-It account.
Research Services
Archive-It Research Services provides partners with the ability to download datasets extracted from their collections, such as key resource metadata elements, named entities, or linking patterns. These datasets can be provided to researchers and users, allowing them the ability to access and analyze partner web collections in bulk and for use in analytical methods such as data mining, visualization, and other computational analysis.
Partner Support
Highlights:
- New Help Center for all partner support needs
- Brand new, thoroughly revised, and enhanced tutorials
- Quick access to partner support system
The new 5.0 user interface and features prompted the review, revision, and improvement of the Archive-It help documentation. The new Archive-It Help Center offers tutorials to guide users through every stage in the web archiving process, FAQs, technical information, and more. As always, partners can reach out directly to our team when you need more information or support. We hope that this upgrade to our help documentation will make the entire web archiving process easier and more transparent for all of our partners.
Information architecture
Highlights:
- New web framework and API for improved querying
- New real-time datastore and analytics engine for crawler logs and reports data
The 5.0 web application's new user-facing front end is now based on Django, a Python-based web development framework. It queries our new real-time, Druid-based datastore through a well-defined API. This will speed future development efforts by cleanly separating the data layer from the presentation layer and by leveraging API-based systems interoperability.
In the process of building a new data engine, we used our Archive-It Hadoop cluster to ingest 10 years of crawler log and scope data – well over 20+ terabytes of data – into the Druid datastore. This system will optimize processing and query speeds for reports data. Moving forward, new crawler log data will be ingested on a real time basis into Druid while a backup copy of the data will continue to reside in Hadoop and the Archive-It data repositories.
Toggle between Archive-It 5.0 and 4.9 interfaces
The legacy Archive-It "4.9" web application will be available for normal use as partners transition to using the new 5.0 web application. During this time, partners can quickly toggle between user interfaces by using the buttons provided at the bottom of each view of the web application:
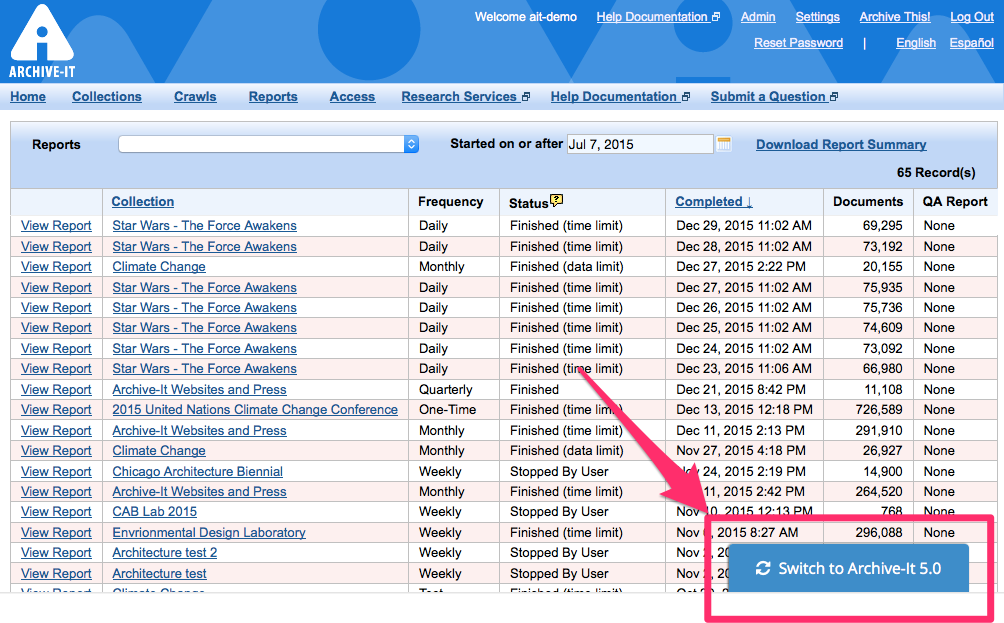
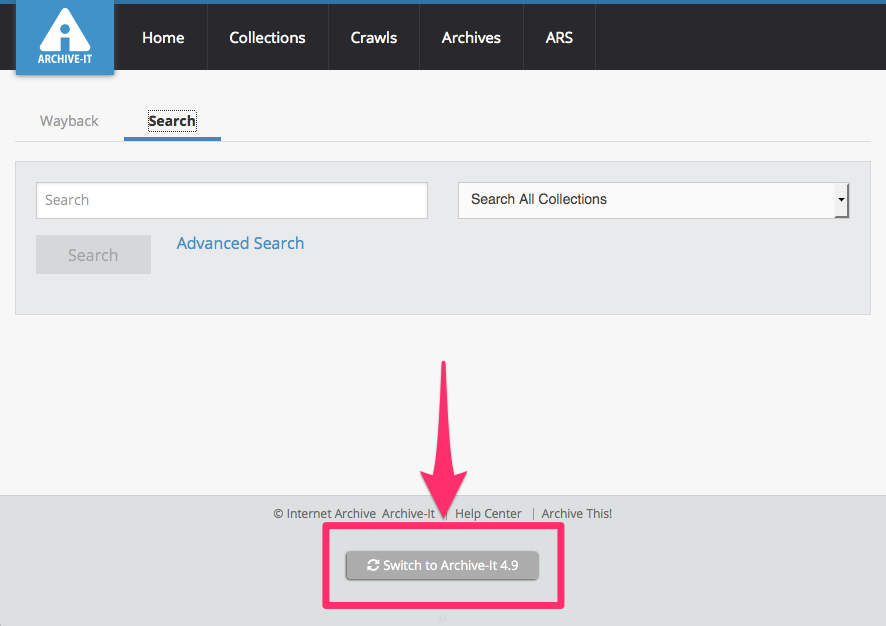
Please note that Archive-It 5.0's many new features are not available in the legacy user interface, so partners are encouraged to transition to using Archive-It 5.0 regularly, especially to take advantage of its increased tools for managing accounts and collections, crawls, metadata, and archived content.
Video Introduction to Archive-It 5.0
This is a recording of the live introduction and demonstration provided to existing Archive-It partners upon the release of Archive-It 5.0. In this training Web Archivists cover the full list of improvements and enhancements, including earlier releases, walk through using the newest tools in the live interface, and answer questions.
Watch:
Download as:
Future Development
Please refer to our most up-to-date reference for ongoing and future Archive-It development.
Comments
0 comments
Please sign in to leave a comment.