
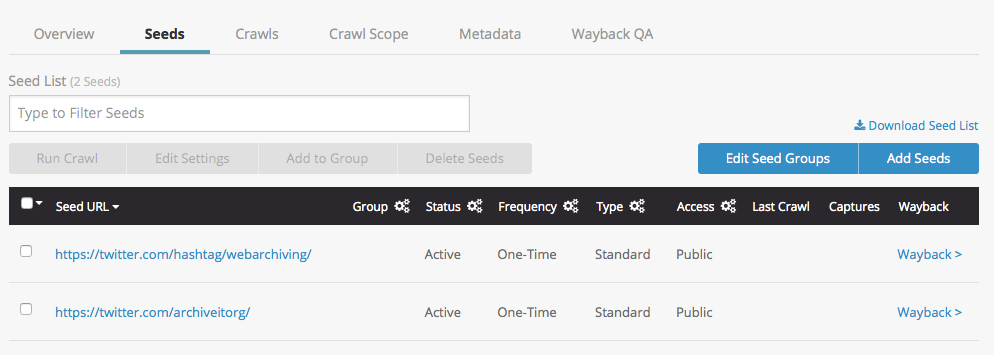
Overview
Twitter is an online news and social networking service. You can add Twitter feeds, including those for hashtags, to your collection in order to crawl, archive, and replay them as you would any other seed site, just so long as you remember to format and scope them according to a few simple rules. This guide provides an overview of how to properly format, scope, and crawl Twitter seeds.
Known issues
Social media platforms like Twitter can be difficult to archive. Recent changes to the Twitter platform present multiple archiving challenges. Currently, Twitter has the following issues which we continue to actively monitor:
- ⚠️ Archive-It can capture and replay Twitter feeds visible to non-logged-in users. This means recent captures may not include the latest tweets.
- ⚠️ For individual tweets with video, media playback may work through the Wayback banner in some cases.
For a full list of known issues please visit our Status of monitored platforms page.
On this page:
- How to select and format your Twitter seeds
- Scoping Twitter seeds
- Running your crawl
- What to expect from archived Twitter seeds
How to select and format your Twitter seeds
It's important to be specific when selecting your Twitter seeds. They can take the form of a specific user's feed like https://twitter.com/internetarchive/, a hashtag feed like https://twitter.com/hashtag/Webarchiving?src=hash/ or a specific search like https://twitter.com/search?q=web%20archiving&src=typd/.
Follow our standard guidance for adding seeds, but remember the following principles:
- Add an ending '/' to the url, for example: https://twitter.com/internetarchive/ (with an ending /). This allows you to archive only the feed that you specify, rather than all of Twitter!
- Use the HTTPS protocol, not HTTP when formulating your seed.
- Do not add www to your Twitter seed. Twitter URLs do not have a www by default, and www.twitter.com is blocked by a robots exclusion.
Scoping Twitter seeds
New Twitter seeds will have default scoping rules automatically applied at the seed level when they are added to a collection; older Twitter seeds can be updated by adding the below scoping rules manually or following these instructions.
To learn more, please visit Sites with automated scoping rules.
Default scoping for Twitter seeds
By default, all new Twitter seeds as of May 14, 2019, will have the following scoping rules applied at the seed level, in order to ensure that embedded images, icons, and glyphs are archived:
- Expand scope into include URL if it matches the SURT: http://(com,twimg,
- Robots.txt will be ignored
If you see this kind of media missing from your earlier Twitter archives, you may apply the above scope adjustment manually and/or in bulk.
How to modify the scope of Twitter seeds
The proper formatting above enables our crawler to access Twitter feeds. To ensure that it also archives all of the proper content it finds there, and furthermore to limit it from archiving too much material from remote areas of Twitter, you may apply the following optional scope modifications:
Exclude additional languages
For any given "tweet," the page is captured in all languages that the Twitter interface supports. For example, for each original tweet's URL archived in the following format...
https://twitter.com/[user name]/[tweet ID]/
...the following URLs are also archived:
https://twitter.com/[user name]/[tweet ID]/?lang=ko (Korean)
https://twitter.com/[user name]/[tweet ID]?lang=es (Spanish)
https://twitter.com/[user name]/[tweet ID]?lang=fr (French)
etc...
If you prefer to prevent multiple languages from archiving, and subsequently from replaying in Wayback, limit the scope of your collection or your specific Twitter seed to block URLs that match the following regular expression: ^.*lang=(?!en).*$
When this rule is added at the collection level, twitter.com should be listed as the host.
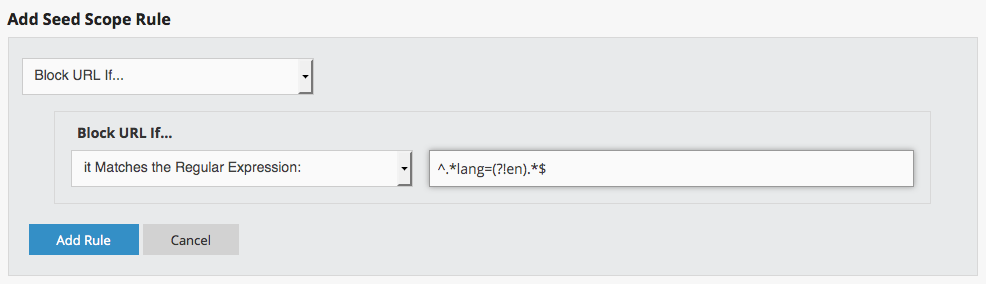
You can adjust this regular expression to allow archiving in other languages by changing the language abbreviation in the parentheses. To archive only Spanish content, for instance, you can use ^.*lang=(?!es).*$ You will need to know the desired language abbreviation to use this rule. Please be sure to run a test crawl after adding this regular expression.
Alternatively, if you'd like to capture more than one language, you can adjust the regular expression by following the format of this regex, which will archive in English and French: ^.*lang=(?!en|fr).*$
Links in Tweets
All links in tweets currently redirect through the Twitter URL shortener, https://t.co/. These links are out of scope by default, but can be scoped-in using the following rules.
To allow our crawler to access the actual pages and contents linked by a tweet, including all embedded files (such as images, CSS files, javascript files, etc.):
-
Expand the scope of your crawl, preferably at the seed level, to include URLs that contain the following text: https://t.co/
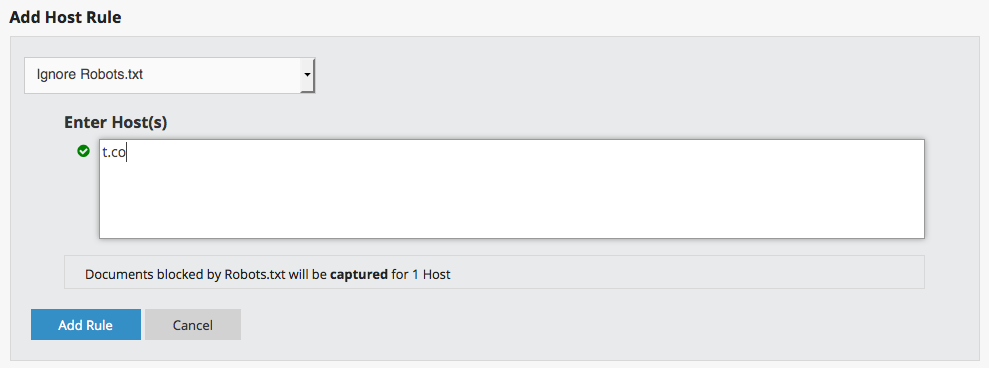
- Ignore robots.txt blocks preferably at the seed level, or (as pictured below) at the collection level on the host: t.co
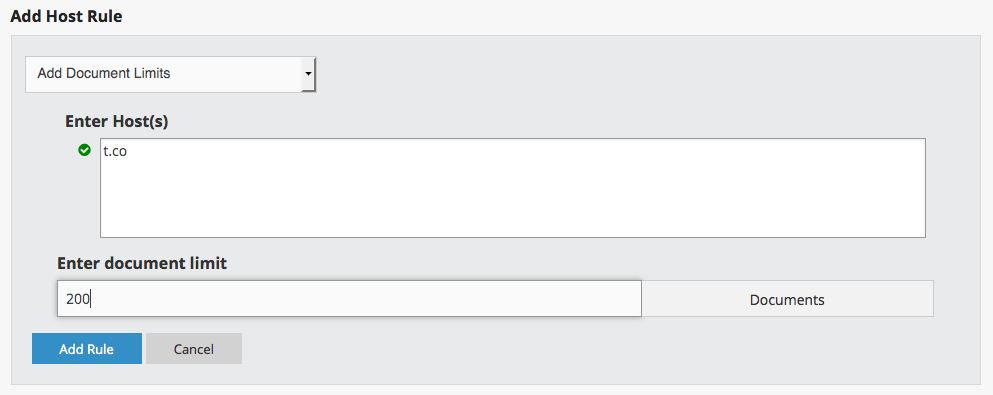
- Document limits allow you to specify how many t.co links off your target seed(s) you want to archive each time. This rule type must be added at the collection level. Try starting with a document limit of 200-500 documents on the host t.co.
- Data limits can also be added at the seed level to specify how much data you will allow t.co to add to your crawl. Try starting with a data limit of 1GB-2GB on the seed.
- Each seed and collection will be different; run a test crawl with the new rule(s) in place to make sure they are entered properly and you're getting the content you wanted. You may need to adjust the limit(s) depending on the results.
Video
To capture all video content, ignore robots.txt blocks for the following host: video.twimg.com This isn't necessary if you ignored robots.txt at the seed level, which means that you will capture video content by default.
Running your crawl
Once you have finished selecting your seeds and adding any recommended scoping rules, crawl your seeds using Brozzler.
What to expect from your archived Twitter feeds
Recent changes to the Twitter platform present multiple archiving challenges:
- As of August 2024, Archive-It can capture and replay Twitter feeds visible to non-logged-in users. This means recent captures may not include the latest tweets. Twitter feeds and hashtags are experiencing collection and replay issues.
- For individual tweets with video, media playback may work through the Wayback banner in some cases.
For historic crawls, you may encounter the following issues:
- From October 2023 to August 2024,Twitter feeds and hashtags experienced collection and replay issues.
- Tweets and their inline images may display in archived feeds, but clicking an individual tweet to see its detail view may not replay, although this data may be captured. Check the twitter.com Host report for documents containing /status/ to see tweets whose detail views have been captured.
- Dynamically scrolling content on search pages might not fully archive or replay.
- Opening multiple Twitter pages at once can cause interference from browser cookies, resulting in an error message. We recommend limiting the number of Twitter captures open in a browser at the same time, and clearing Wayback cookies regularly.
Comments
0 comments
Please sign in to leave a comment.